The project had issues. It was a two-year project intended to swap an aging legacy application for a commercial product. The vendor’s off-the-shelf software required some customization and extension for the (very, very large) customer.
Among other things, the application scheduled classes and tracked attendance. It also docked the pay of people who failed to attend classes for which they were scheduled.
There were a number of extenuating circumstances that led the project to its troubled state, but they are not relevant to this story. Suffice it to say that a new project manager (a friend and client) had been brought in late to the process—about six weeks from the proposed go-live date—and had just discovered that the only planned testing was users banging on keyboards to assure that the commercial application “met their needs.” What the users could touch was mostly the non-modified parts of the commercial application, and finding errors there was unlikely.
When we looked under the covers, we discovered the customizations required of the commercial application involved swapping about a dozen files with existing customer legacy applications. These interfaces were direct replacements of files that the legacy application (being retired) had used to pass data to other client systems. Existing plans omitted any testing of these interfaces. Yikes!
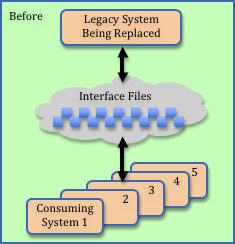
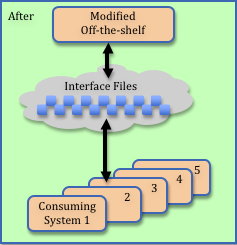
When asked to help triage the situation, my first assumption was: “If the legacy applications that consume the interface files are programmed defensively (e.g., validating all the data they received before further processing), then perhaps exhaustive testing won’t be necessary.” I was thinking that bogus data would be detected and that this might allow us to go live and then monitor for problems while we retroactively reviewed and tested.
A quick consult with the application team that supported the consuming systems dashed those hopes. The legacy systems had been built to “trust” the files they consumed and used them without validation. (Note to developers: “Trusting” interfaces decreases modularity in the future. It’s faster and cheaper in the short term, but sometimes you repeatedly pay a premium for the shortcut.)
Armed with this information, my next thought was: “Unfortunate. If we don’t want to contaminate the legacy environment, perhaps we should perform complete data validation of the incoming interface files.” This was a reasonable and conservative default assumption to protect the consuming systems. We could have stopped there and insisted that validation programs be created for each of the interface files, but that would likely threaten the planned go-live date. To estimate this effort and to confirm whether it was necessary, I needed to get more information about the interface files—their complexity, size, and how their consuming systems used them.
I rolled up my sleeves and dove into the specifications. It wasn’t as bad as I had feared at first. Of the dozen or so files exchanged, I discovered the following:
- Several fed internal reports and could probably be “eyeballed” for quality purposes after going live. The consequence of bad data would be minor annoyance and easily detected. The reports were consumed internally. It was probably safe to go live without testing these and then monitor the reports in the interim while testing more extensively after going live.
- Some of the files passed information about scheduled classes back and forth—the worst case being that a class might be scheduled for February 30 or have zero slots available. Since this information was fed from user-entered data in the new commercial component, it was reasonable to assume that the commercial application did some preliminary validation. Furthermore, the consequences of erroneous data were not fatal in an application context. The class schedule could be “eyeballed” after going live to detect and correct errors, again allowing deferred testing.
- Three of the files set flags that affected payroll. This was a big deal. If you want to get people’s knickers in a twist about your new system, screw up their paychecks and listen to them scream.
The three payroll-affecting files were the biggest risk of going live without thorough testing. The conservative response of the technical advisors on the project was “We can’t go live without thorough testing and validation of these three files.” The trouble was that these files would be difficult to validate without fully functional production data (for a variety of reasons—just trust me, it was hard). This meant a certain slip to the go-live date, which had a variety of negative consequences.
My client, the project manager, and I met to review what we had learned so far and to determine whether there were any options that allowed us to keep the go-live date without risking the success of the project.
We agreed that stopping payroll erroneously was an unacceptable outcome. The question was whether we could find a way to avoid that outcome without slipping the project schedule. Looking at the data flows—the information shared with you thus far—we didn’t see a way. Then, we thought to look at the record counts. The number of stop-pay records in a typical week was a few hundred. We realized that if we trapped the file after the commercial system created it and had users manually confirm all of the stop-pay records by looking up the necessary individuals and assuring that the appropriate conditions were met, we could avoid the worst-case scenario of erroneously setting the stop-pay flag. This might require a full-time clerk to review the file each day until testing was complete.
The final decision was that we could probably go live without testing the interfaces, provided we were willing to expend resources on carefully monitoring the results after the go-live date. This didn’t mean that testing and validating the files wasn’t necessary, just that we didn’t have to delay going live to wait for it. Validation routines could be added after going live.
From a project management perspective, I was pleased with the detective work that we did and the final recommendation. By throwing additional resources at the problem (the clerical resources necessary to monitor key indicators after the cutover), we were able to mitigate the risk of keeping with the scheduled go-live date, which was important to the client for a variety of reasons.
I believe the thought process we went through was worth sharing. From initially believing that it was impractical and dangerous to go live without thoroughly testing the interface files, to peeling the onion to determine the real risks and costs, to discovering alternatives that we could propose, it was an excellent, real-world example of project management and technical triage. I was proud of the outcome.
While I’ve fuzzed some of the details above to protect the client’s confidentiality, I would be happy to answer any questions you have in the comments below.


")

Lets Hang!