AI-powered code generation tools like GitHub Copilot, Cursor, and Claude now dominate the development landscape. Developers can create automatically generated code with these tools in seconds, significantly increasing their productivity. According to last year's report, 84% of developers already use or plan to use AI tools in their development processes.
In practice, code written with the help of AI produces different results than code written entirely by humans. It often appears well-structured, quite plausible, and most likely passes all sorts of automated checks, while hiding subtle errors or vulnerabilities that appear later in the release pipeline. For QA teams, this means that traditional testing approaches may miss new categories of risks for code written with AI, and to maintain software quality and security, the team must adapt to new development conditions and processes.
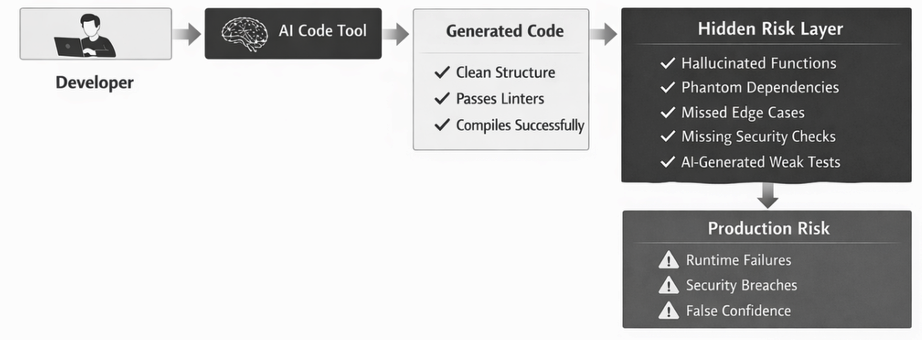
Hallucinations: Nonexistent Functions and Phantom Dependencies
One of the strange phenomena associated with AI-powered code generation is hallucination. Sometimes, AI can create references to code that doesn't actually exist. For example, AI can confidently make calls to a library function, and these functions may sound correct, but in fact, they may be completely fictitious. These hallucinatory functions can even compile or execute until they encounter phantom calls, causing runtime errors.
Community experience shows that approximately one-fifth of the external dependencies suggested by AI represented non-existent packages. The problem is that this isn't just a harmless feature of artificial code generation but a problem if a developer thoughtlessly adds these suggested imports, which could pull in a malicious package with a similar name, also known as typosquatting, or an AI package hallucination attack.
These kinds of issues can force QA engineers to view any generated code with skepticism, leading to double-checking. Static analysis or code review is crucial here, and if the generated code adds a library, its legitimacy and security must be verified. Testing processes should no longer be based on trust and will require a more thorough approach.
Missing Edge Cases and Business Rules
AI-assisted programming tools excel at generating code for optimal and obvious scenarios. However, it can miss rare cases, error handling, and implicit business scenarios that may be important for the product. This happens because AI generates code based on static patterns without a detailed understanding of the context of the function or problem. The result is aesthetically correct code that may work correctly for happy-path scenarios but may fail in extreme cases that an experienced developer with an understanding of the specifics and subject area would notice.
AI-generated functions may fail to handle non-standard or unusual input data, leading to unhandled exceptions or unexpected results. This only becomes apparent when boundary conditions arise. AI might generate a function to process a list of records, but it might fail to handle an accidentally empty array, a null input value, or other scenarios that AI can't predict. This code might pass basic checks and unit tests, but will fail when faced with something that was out of scope.
Hidden Security Gaps
Developers frequently point out that AI-based programming tools were trained on publicly available code, which may include both secure and insecure patterns. It means that AI tools may repeat old mistakes or skip critical security measures. AI tools often omit authentication checks unless the developer explicitly requests them. An AI-driven tool could create a web endpoint that returns data without checking for a JWT in the HTTP request. This code would be functionally valid from a development perspective, but would contain a security hole in production.
Another well-known issue is the use of outdated or insecure methods. Vendors trained most models on vast amounts of legacy code, and they suggest solutions that were common at some point but are now outdated or vulnerable. This can include outdated cryptographic algorithms, outdated libraries, or inefficient or insecure configurations. AI might suggest using an older version of a JWT library with a known vulnerability, or an outdated password hashing method. Also, if the project’s codebase contains bad examples, the AI can pick them up and spread them further.
AI-Generated Unit Tests: False Confidence and Partial Coverage
Developers also use AI tools to generate unit tests, and at first glance, this seems like a big advantage for QA engineers and project quality, because the more tests, the better the code coverage. Most AI-based test generation tools analyze code and generate tests to verify its current behavior. This means that AI does not verify that the code output meets the requirements; it simply creates a mirror image of the implementation. As a result, you can get tests that will always pass even if the code does not work correctly from a business perspective.
Here’s a simple example:
public static int divide(int a, int b) {
if (b == 0) {
return 0; // bug: should throw an exception
}
return a / b;
}
An LLM may generate this “unit test”:
@Test
void testDivideByZero() {
assertEquals(0, MathUtils.divide(10, 0));
}
This test will pass, but only because it codifies the bug as a feature. The AI determined that the code returned 0 for divide by zero and assumed that this was intended behavior. Thus, the test didn't reveal the bug, but confirmed it. It's precisely these kinds of tests that create a false sense of security and turn existing bugs into confirmed behavior.
The next problem is that AI-generated tests only have happy-path coverage. Often, tools focus only on common scenarios and rarely consider unusual or unexpected inputs or conditions that could cause errors. They can often test a few basic scenarios and stop there. In one benchmark, AI generated unit tests showed high line coverage for simple functions, but for functions with multiple logic branches or boundary conditions, the AI-generated tests only covered approximately 60% of the test coverage. Thus, it's not uncommon to encounter test suites that miss entire nested functions and exceptions, yet the tests pass only because they never touch complex sections of code.
Another problem may be that AI-generated tests may be poorly designed, which could lead to complex failures or high maintenance costs in the future. Such tests may contain hard-coded values or make assumptions about external services or integrations. For example, a test written by AI for a function that calls an API might not include mocking, thereby calling a real endpoint in the context of unit testing. Tests may also use strange or cryptic variable names and may not have a clear purpose, which will make them difficult for humans to maintain in the future.
Adapting the QA Process for AI-written Code
The amount of AI-generated code will only increase in the future as it truly improves productivity. Therefore, QA teams should adapt their processes to identify new types of failures and mitigate risks. Here are some ideas on what can be done from QA perspective to adapt the process for teams where developers use AI tools for programming:
- Treat AI contributions as “untrusted code.” Teams must implement a policy requiring that any new code generated by an AI assistant be subject to the same review process as code created by junior developers. This means mandatory code reviews, security scans, and testing of the most basic aspects.
- Raise the testing bar on AI-written code snippets. It's important to require a higher level of test coverage and rigor for AI-generated code than for human-written code. Since we know AI is likely to miss edge cases, the QA department should develop additional tests for these cases. It's also necessary to pay closer attention to negative scenarios and rare conditions in your project for modules written using AI.
- Augment CI with guardrails and quality gates. It's necessary to integrate tools to automatically identify issues in your code. This includes Static Application Security Testing (SAST) tools for security, linters, or various static analyzers for code quality assessment. It would also be a good idea to add dependency scanners to detect outdated or risky libraries. In addition, Dynamic Application Security Testing (DAST) can help catch issues or anomalies that only appear at runtime, including failures caused by phantom dependencies or broken integrations. Configure your CI/CD so that builds containing critical security issues fail. Teams can use GitHub Dependabot or Snyk to detect when an AI-suggested package has known CVEs, or OWASP Dependency-Check to block untrusted dependencies.
- Track AI-generated code. Practical industry advice is to mark AI-generated code, so reviewers can approach code reviews more thoroughly. This transparency helps QA teams understand when additional complexity is required. Over time, you can also track the number of defects in AI-generated code compared to human-written code.
- Redefine “Definition of Done.” When AI is involved in development processes, the traditional definition of readiness may be irrelevant. In this case, you can expand your readiness checklist to include several new items, such as "all AI-generated code has been manually reviewed and has appropriate test coverage," "static analysis has passed successfully," and "business logic has been verified with the product owner."
- Continuous learning and audits. Build your process so you can discuss any defects found in AI-generated code with your development team quarterly. Feedback helps developers understand how to adjust their AI process to minimize the risk of missed defects.
Final Thoughts
The use of AI tools significantly accelerates development, freeing teams up for other tasks. At the same time, this creates new risk profiles that QA teams must consider to ensure quality. QA teams must redress the balance between the speed of AI and the wisdom of rigorous testing and human oversight. QA teams should evolve their strategies, including more rigorous checks, more thoughtful test design, and automated protection mechanisms that detect anything missed by AI. By understanding these new risks and adapting their processes accordingly, QA teams can ensure that accelerated development doesn't lead to disruptions in production. Tools may change, but the mission of quality assurance remains unchanged.
I don't mean to criticize artificial intelligence tools in any way. I see these tools as the future, and I even use them daily myself and see many advantages, but that's a topic for another article.





Lets Hang!