This is the second part of a four-part series addressing software performance testing. The first part originally appeared in the April 2009 issue of the Better Software magazine. You can also find part one on StickyMinds.com.
The general outline of topics in this series is as follows:
- - The role of the tester in the process
- - Understanding performance and business goals
- - How software performance testing fits into the development process
- - Selecting the types of tests to run
- - Quantifying and defining measurements
- - Executing the tests and reporting results
- - Understanding tools
- - Quantifying and defining measurements
- - Executing the tests and reporting results
- - Understanding load (operational profiles OP)
- - Selecting the types of tests to run
- - Quantifying and defining measurements
- - Executing the tests and reporting results
- - Understanding tools
- - Quantifying and defining measurements
- - Executing the tests and reporting results
- - The system architecture and infrastructure
- - How software performance testing fits into the development process
- - Selecting the types of tests to run
- - Quantifying and defining measurements
- - Executing the tests and reporting results
- - Understanding tools
- - Quantifying and defining measurements
- - Executing the tests and reporting results
- - Understanding load (operational profiles OP)
- - Selecting the types of tests to run
- - Quantifying and defining measurements
- - Executing the tests and reporting results
- - Understanding tools
- - Quantifying and defining measurements
- - Executing the tests and reporting results
 In part two of the series I will focus on dealing with architecture and infrastructure issues and selecting the types of tests available to testers. The goal here is not to address every possible aspect of architecture and infrastructure or all possible test types, but to provide a general set of guidelines that can be used in developing a reasonable software performance test plan.
In part two of the series I will focus on dealing with architecture and infrastructure issues and selecting the types of tests available to testers. The goal here is not to address every possible aspect of architecture and infrastructure or all possible test types, but to provide a general set of guidelines that can be used in developing a reasonable software performance test plan.
System Architecture and Infrastructure
The test architecture and infrastructure is probably the most common reason software performance tests results are invalid. To properly test a system or application, there are several key elements that must be looked at to ensure the test has at least a reasonable chance of providing useful information.
The first areas we will look at are issues relating to the physical architecture. There are two primary elements here: 1) the applications and systems, 2) the platforms on which the software will operate and 3) the network (if one is involved).
If the physical layout of the test system is substantially different from the production or target system, the test may not provide accurate performance data. When we look at the physical layout of a system, there are several key
elements that must be addressed.
The physical footprint of the system is critical. If the production system is a multiple-server system working in clusters but the test system is a single server or non-clustered individual servers, depending on the scalability factor, the test may have no value at all. The scalability factor is the ratio of equipment used in the test as compared to the actual target environment. A scalability factor of 5:1 or greater may yield no useful results. Some believe that a ratio of 10:1 is acceptable, but I find that once you get beyond 5:1 the differences can be dramatic in certain aspects of the architecture and infrastructure.
Figure 1 shows a 3:1 scale model.

Figure 1
This may give us reasonable numbers, but they will not be a guarantee of what will happen in the production world. There is also a missing element to this picture. To have a "cluster" of servers you need some form of load balancing. The test lab configuration does not have this element. By their nature load balancers are a bottleneck,
as all traffic must pass through them to reach the individual servers.
In addition to the physical layout issues of scalability, we also have to examine the internal characteristics of each platform that will comprise the test, as shown in figure 2.
Production | Test Lab |
Three servers per function | One server per function |
DB server | DB server |
10CPU, 20GB memory | 2CPU, 10GB memory |
APP server | APP server |
20CPU, 10GB memory | 2CPU, 10GB memory |
Web server | Web server |
5CPU, 10GB memory | 2CPU, 10GB memory |
Has a load balancer | Has no load balancer |
Figure 2
The overall model in the test lab is 3:1; however, the following areas are suspect. The reason they are suspect is the sub-bullet following each element. This first bullet pair describes one system and production. The second pair describes the test system; they are substantially different in terms of scale.
- The DB server in production is 10CPU sharing 20GB memory
- The relationship is 1CPU to 2GB memory
- The DB server in test has 2CPU sharing 10GB memory
- The APP server in production is 20CPU sharing 10GB memory
- The relationship is 1CPU to .5GB memory
- The APP server in test has 2CPU sharing 10GB memory
- The Web server in production is 5CPU sharing 10GB memory
- The relationship is 1CPU to 2GB memory
- The Web server in test has 2CPU sharing 10GB memory
Internal differences in architecture can create or hide problems in the test lab that may not occur in the production system. If you adjust the application or system for the problems discovered in the test lab, you may be making a fatal mistake when the system goes into the production architecture.
Certain aspects of the architecture and infrastructure are especially risky when looking at scale models. Some relational database functions tend to behave very differently at differing scale models. There are many aspects that require investigation:
- Number and size of drives
- Distribution of tables and data on drives
- Mix of data in tables
- Use of indexes, keys, semaphores, etc.
- Use of database controls
- Referential integrity, stored procedures, etc.
- Type of connection
- Physical attributes
- RAID, Mirrored, etc.
- Shared by other applications
When assessing the physical layout and scalability issues associated with the architecture infrastructure, we also need to consider the nature of certain elements. Many elements within the architecture are non-linear. Adding equal amounts of a resource does not add an equivalent level of performance.
Look at the CPU within a system. If a single processor can support one hundred users, then adding an additional processor should add 200 users, right? No, this will not happen. The two processors will consume part of their ability communicating with each other. Add a third and the level of additional supported users increases, but again, at a decreasing rate. Eventually, adding another processor may create a negative effect and reduce the total number of users supported.
A simplified example for CPU scalability is shown in figure 3.
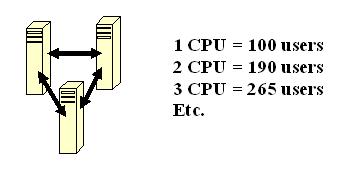
Figure 3
This brings us to the last element of the architecture and infrastructure-the network. Networks are complex systems that are very similar to a plumbing system. Small pipes connect into larger pipes that in turn connect into even larger pipes. Information has to move from the small into the large and back again. There may even be some control points (valves?) to regulate flow etc.
How does the network in the test lab compare to the production environment? As with every aspect of the architecture and infrastructure, there are several key issues that need to be addressed, as shown in figure 4.
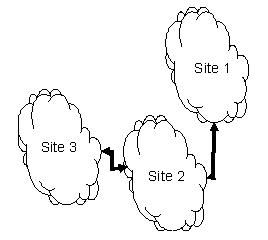
| Network type and configuration
LAN, WAN, Internet, etc.- Dedicated or shared network?
Number of physical elements
Bridges, routers, gateways, etc.- Non-application elements (firewalls, etc.)
Bandwidth Configuration
Star- Bus
- Ring
- Hub or switched
- Etc.
|
Figure 4
What if the necessary equipment is not available? Can a scale model be used to represent the real world and then "predict" what may happen? There is a popular concept relating to this, "extrapolation," which I discuss later. Scalability is the capability of a system to expand and contract as the level of activity on the system changes and to provide acceptable service as the load increases or decreases. Simply put, systems and applications must be able to handle large as well as small loads.
There are two ways of looking at the scalability of a system or application:
- Scaling within the current architecture (an aspect of capacity planning)
- Testing for the bottlenecks that prevent the system from handling larger workloads
- Testing system features and characteristics that are unnoticed or irrelevant for small-scale operations but which become vital as the use of the system grows
- Scaling the architecture itself, once the current system has reached its usable capacity
- Requires the addition of the necessary architecture and infrastructure in order to perform the tests
Because these types of tests require large amounts of architecture and infrastructure to represent the actual target environment (and to support the load generation tools), most organizations cannot afford the costs, which brings us back to the concept of extrapolation.
Extrapolation is a method of scalability prediction. The system is tested on an increasingly larger series of platforms, databases, or networks or with an increasingly larger series of loads. Performance characteristics are measured and graphed against the size of the infrastructure and the size of the load. The performance test team extrapolates the full size system or application's behavior from the plotted trend chart.
The problem is will it be accurate? Extrapolation is essentially a linear prediction of system capabilities. As we noted earlier with scalability issues, systems and applications tend to be non linear in many key aspects. If your environment is not in balance, the prediction becomes even more inaccurate.
This technique is crude and potentially disastrous when applied to reasonably complex applications or systems. It is best to test with as realistic an architecture or infrastructure as possible and not extrapolate.
It is possible to use extrapolation in very limited circumstances. If the performance test is narrowly focused on a single component or aspect of the system, and that element has linear characteristics, then the method can be
applied.
- For example, evaluating the amount of space consumed on the database by a set of transactions is a linear concept. The dispersal of the data may or may not use a linear algorithm. If the focus is limited to disk consumption the model will work, as each transaction consumes a specific amount of storage.
As we have seen, the architecture and infrastructure required for a reasonable performance test is very difficult to define and manage. Even if we cannot address all the issues I've identified here, the test may still have some value in areas such as avoiding disasters. If the system fails in the test lab, then the odds are the production system will also fail.
Selecting the Types of Tests
When deciding on a type of performance test, we must first know the problems we are trying to solve. This is why I focus on the elements of a performance test in the order shown in the outline for this series of articles. Once you know the overall goals of the test and have an understanding of the problems, you can select a test or set of tests to investigate those problems.
Typically we look at performance tests as falling into three general categories:
- Testing based on the source or type of the load
- Testing driven by what we want to measure
- Testing to stress the system or find its limits
Each of these categories in turn has multiple subcategories or variations. I will not attempt to address all possible variations here but focus on a small subset of each type. These test types will be able to answer most of the issues we have discussed in the earlier parts of this series. We will look at each category in turn.
Most performance tests are a combination of one or more test types from one or more categories as we will see after we look at the types.
Testing based on the source or type of the load
- Usage-based testing: Exercises the system in test mode the same way as in live operation, according to its operational profile.
- User Scenario: A real-world set of activities, based on how users actually utilize the system. Feature testers develop conventional tests using standard test case design techniques, like boundary value, deriving the test cases for one feature at a time. This tends to under-represent complex interactions among transactions.
- Standard benchmark tests: Uses a standard workload rather than a user-specific one, when it is difficult to discern how a system actually will be used. Most commercial benchmarks are published through the TPC.org.
- Load variation and bounce testing: Varies the test load during the performance measurement to reflect the typical pattern of how real-world loads ebb and flow over time. The system needs to scale appropriately as defined earlier.
- Scalability testing: Investigates a system's ability to grow by increasing the workload per user, the number of concurrent users, the size of a database, the number of devices connected to a network, and so on.
- As we noted earlier, there are two types of scalability. Scaling within the current architecture and infrastructure to assess capacity and scaling the architecture and infrastructure itself.
- Component-specific testing: Examines the performance and robustness of one system component (or sub-assembly). This can be done as soon as the component is ready, before other components are built and well before the fully integrated system is ready for testing.
- e.g., focused testing on the database only or the network only
- Calibration testing: Checks a system against mandated requirements such as those from a government regulatory agency or an internal service level agreement (SLA).
Testing driven by what we want to measure
- Response time testing: Measures how long the system takes to complete a task or group of tasks.
- The most common focus of response time is from the user or customer perspective.
- Some response time tests may be component and SLA driven, such as testing a third-party interface such as credit card processing for an e-commerce application.
- Throughput testing: Measures an elements capacity, such as how much traffic passes through a point in the system or how many tasks are completed within a specified period of time and under a specified load.
- Availability testing: Records the percentage of uptime for a system or component.
- A common industry measure is referred to as the five nines-99.999% availability. This is a very high level of both availability and reliability.
- Resource utilization testing: Monitors the levels of utilization of system resources such as memory, CPU, threads, etc.
- Error rate testing:Some refer to this as "robustness." Measures the error rates of features or functions when the system is under normal or heavy load. As the load increases or changes the potential for errors increases.
- Can the system or application handle the increase in errors? Fast response and high throughput are irrelevant if the user cannot do his job.
Testing to stress the system or find its limits
- Ramp-up testing: There are several interpretations to this concept.
- Measures the time needed to initiate a process.
- e.g., let's say an inactive network device is triggered when there is work for it to do and it must be able to begin working within fifty milliseconds.
- The term ramp-up test also refers to the need to gradually ramp up a test load to full strength to avoid overwhelming a system during start up.
- In extreme circumstances there may be a sudden surge of activity on a system. An example of this would be users attempting to log back into a system after a crash. The sudden surge of activity may cause the system to fail again.
- Duration or endurance testing: Some refer to this as a form of reliability testing. Runs the system for extended periods of time (days or weeks) in continuous operation in the test lab to detect long-term types of defects, like slow memory leaks. This can be especially important for 24/7, always-on systems such as e-commerce applications or ATMs.
- Hot spot testing: Focuses a heavy, targeted load on a specific, limited portion of the system in order to detect if it is a weak point. We employ this in areas we suspect are vulnerable, like the weak links in a chain.
- This type of test may also occur as a natural part of an application. An example would be e-commerce Web sites that sell special occasion gifts. These sites can expect a huge surge of activity around certain holidays (Valentine's Day, Mother's Day). However, the targeted products for those surges would be very different. On Mother's Day, the activity would be all over the site, but on Valentine's Day, most of the activity will be focused onto a single product (long-stem red roses and chocolates) creating a "hot spot" in the application.
- Spike testing: Utilizes intense spikes in the work load-for very short durations-to determine how the system handles abrupt increases in demand. This tests whether the system can respond to rapid significant changes and redirect the use of its resources, for example, through load balancing.
- The validity of this type of test will depend on the type of system being tested.
- Mainframe, LAN/WAN, and intranet types of applications have a fairly finite potential-the number of devices attached to the system.
- Web- or Internet-based applications have a nearly infinite possibility for access. Certain security attacks-denial of service and distributed denial of service-are examples of extreme loads from hackers.
- Breakpoint or failover testing:Increases the load until the system fails or increases the load as much as feasible within the constraints of the test environment. It may not be possible to generate sufficient load to crash the system, depending on the load generator used (number of licenses is a key factor).
- This can be a useful test if the system engineers have built in safety features such as application throttles. These are built-in controls designed to keep the application or system from crashing.
- Deadlock testing: Runs high-volume tests (possibly from different application sources) to detect if there are resource contentions in the system such as multiple requestors trying to access the same database and causing the system to lock up the user request due to conflicts in areas like database record locks.
- Degraded mode of operation testing: Determines whether the system can still provide the (possibly reduced) level of service as expected, when not all of the resources are working. (An example of a degraded mode test is to deliberately power down a server, in a server cluster with redundant application servers, and attempt to continue normal operation.)
Which types of tests you decided to use depends on the performance goals identified earlier and where the potential problems may exist in the application, system or infrastructure. Usage and stress types of tests are typically combined with measurement types of tests. We use the operational profile (covered in part three of the series) to create the type of activity we need on the application or system and then measure those areas to are interested in.
If we are interested in end-to-end response time from a user perspective, we would run usage-based tests combined with measurement types of tests, (measure CPU, memory usage, threads, etc.). We need to combine several types of tests as we do not know where the problems will occur, if there are any. If we see questionable response times, we need the measures to help the technical members of the performance test team locate and resolve the problem.
Now that we understand the performance process, performance goals, and have addressed the architecture and infrastructure issues, we need to focus on the content of the test. In the next part of this series, I will look at defining the load (Operational Profile OP) and measurements to be taken during the test.
Read "Understanding Software Performance Testing" Part 1 of 4.
Read "Understanding Software Performance Testing" Part 2 of 4.
Read "Understanding Software Performance Testing" Part 3 of 4.
Read "Understanding Software Performance Testing" Part 4 of 4.


")

Lets Hang!