Though I am open to the ideas expressed in the Context-Driven School of Testing and Bach's Rapid Testing in particular, my own background in software testing (and development before that) is in a more traditional approach. However, for the purposes of this article I will confine myself to traditional testing, which I define as testing code against specifications via repeatable, scripted test cases.
Testing makes science unique, and it makes testers unique too! Physicist James Trefil (2002), in the introduction to Cassell's Laws Of Nature, stresses the importance of testing to the scientific method:
"This reliance on testing is, I think, exactly what makes science different from other forms of intellectual endeavour. To state the difference in its most blunt and unfashionable form: In science there are right answers."
Although Trefil clearly did not intend to insult software testers by implying that testing is only relevant to science, I've taken this as a bit of challenge, like a gauntlet slapped across the face of software testers everywhere. Testing is somewhat integral to another form of intellectual endeavor, namely software development. But software testing is not generally regarded as a science, nor does it typically feature strongly in computer science. So, what is the relationship between the scientific method and software testing?
Just like science, in software testing there are right answers. Either the software satisfies the requirements or it does not. Either each test case passes or it fails. Through such small incremental black-and-white steps do software testers approach the "truth" about software. In the end, either the software is judged to work, or it does not (and has documented outstanding bugs). Often it is not as black and white as we would like ("What requirements?" or "That's a change request, not a defect!"), which only makes our efforts less scientific and thus less effective. Shades of grey require negotiation, clarification, and definition. The aim is to have as few vague, grey shadows cast over your software as possible.
Test Cases And Experiments
Does that mean that we software testers are scientists? In a way, I think we are. We are the experimental scientists in the field of software development. Yet scientists do not regard themselves as infallible, nor should software testers. We are just as human as developers, and we can make mistakes too. Insufficient test coverage, poorly designed test cases or test data, a badly prepared or supported test environment--these are just some of the common human challenges in software testing (and, I suspect, in science).
Kaner, Falk and Nguyen (Testing Computer Software, 1999) refer to test cases as "miniature experiments" and argue that a good tester requires "An empirical frame of reference, rather than a theoretical one."
Observation is certainly a key asset for a tester, though I will argue that science (and testing) advances through testing theories while eliminating bad ones, through falsificationism.
Kaner draws upon falsificationism theory and the value of experiments in What Is A Good Test Case?: "Good experiments involve risky predictions. The theory predicts something that people would not expect to be true."
If all a tester did were design test cases that he or she knew would always pass, little value would come of the effort. A specification was written, a developer codes based upon this specification, and everyone at least hopes (if they do not expect) that the code works as specified. The testers job is to attempt to try and pop that bubble of expert belief and blind faith. (See figure below.)

Again on the topic of test cases, Kaner wrote, "In my view, a test case is a question you ask of a program. The point of running the test is to gain information, for example whether or not the program will pass or fail the test."
Kaner also points out that "A test provides value to the extent that we learn from it."
Paraphrasing Kaner:
- What do we learn if we re-run same test cases that already passed?
- What do we learn if we run too many similar test cases?
- Does the opportunity cost of designing and running the test case exceed the expected value of what you will learn?
Testing And The Scientific Method
Bret Pettichord in "Testers and Developers Think Differently" (STQE magazine Jan/Feb 2000) wrote: "Good testing is governed by the scientific model. The 'theory' being tested is that the software works. Good testers know how to design experiments. Developing software, on the other hand, is much like creating theories. Good developers think theoretically."
In fact, each test case is designed to test only a small part of the overall theory that the software works. Sub-theories of this overriding theory include that Function A works, Function B works, and so on. If ten test cases are designed to test the theory that Function A works, then all ten must pass for that theory to be tentatively considered true. This is why it helps for testers to think theoretically, as well as empirically. All we can do is reduce the mystery and move the software ever closer to the certainty that it works. But total certainty is a bit like approaching the speed of light--kind of tricky in reality.
In traditional testing, the theory that the software works is itself based on the theory that the code delivers what was specified. I refer to this as the traditional tester's triangle of truth. (See figure below.)
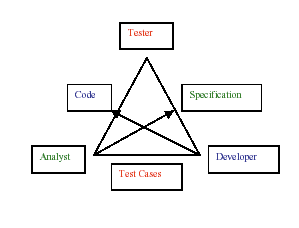
So, when we write a test case, the expected result is based on what was specified. The purpose of running a test case then is to check the theory that, for this small part of the application, the code matches the specification. Defects in the code are not the only reason causing test cases to fail. It could be the test case misinterprets the specification, which the developer got right. It could be the specification wasn't specific, and the developer (rather than challenging ambiguity up front) coded something anyway. It could be all sorts of things. However, regardless of what the root cause of the test case failure is, what you have is an experiment where the predicted result did not happen.
If we accept Bret Pettichord's definition of a bug as something that bugs someone, then even when there are no specifications testers can still raise bugs. In this instance, bugs themselves represent wrong answers to the valid questions that testers are asking about the software. An interesting question here is how do you know you are asking valid questions if you have no specification? Still, for the moment, let's assume you have some verifiable basis for your opinion.
Once a bug is fixed, someone must run one or more experiments (test cases) that attempt to disprove the (new) theory that the bug is fixed. Right answers can only occur when the expected result of a repeatable test case-one to test the fix-is matched by the actual result. Otherwise, once again, all you have is unscientific opinion that cannot be subject to testing. Carl Sagan (The Demon Haunted World, 1997) referred to this sort of unscientific opinion as the Dragon In My Garage problem: "Claims that cannot be tested, assertions immune to disproof are veridically worthless…"
In the case of a bug based solely on someone's opinion, you have the assertion: "It's there, and you can't prove it's not there!" In the case of the bug fix not subjected to testing via a repeatable test case, you have the assertion that "It's not there anymore, and you can't prove it's not there!" My advice is to be wary of the dragon-in-the-garage type of assertion when it rears its ugly head.
Thus, falsification is just as essential to software development as it is to scientific development. Whereas in science the falsification criteria is often used as a demarcation between science and non-science, in software the falsification criteria demarks the testing discipline from the analysis and development disciplines.
As it is in science, so it is with software. Your software is defect-free, you say? A single defect can prove you wrong. The presence of just one defect will prove that your theoretically defect-free code is not, in fact, defect-free
In fact, testing thrives on doubt just as science does. Fix and re-test that single defect, and the odds are that if you keep paying me to keep testing, then I'll find another defect, and another, and so on.
Testing is as precious to software development as it is to science. Yet it seems that we can never finish testing. Surely this can't be right? Of course this is not true or even practical, and that is why we are still apprehensive (to some degree) when software exits the finite test phase and goes into production.
Unnatural Nature Of Software Testing
In Lewis Wolpert's book, Unnatural Nature of Science, he states science is unnatural because common sense is not overly useful in understanding the reality of the world about us. Science is counter-intuitive; it progresses by disproving things rather than proving anything. But for Wolpert, the falsification criteria for a theory to be judged scientific are not enough. Wolpert states that "alsifiability is a necessary, but not a sufficient criteria."
The other criteria he lists are:
- Phenomena that is capable of independent verification
- Self-consistent ideas
- Explanation fits with other branches of science
- A few laws or mechanisms can explain many complex phenomena
- Quantitative and expressible by mathematics
Common sense can let a software project down. Things often start going wrong at the project planning stage, get worse during the requirements stage, get set in concrete during development, and then handed to testing (often late and/or over budget) as a product which works--in theory. Common sense is not enough when testing software.
A defect that is reproducible is a "phenomena that is capable of independent verification." Testers look for "self-consistent ideas" during static testing of documentation. Are the requirements accurate, consistent, and unambiguous within each specification? What about consistency between specifications?
In What Branch of Science Does Testing Fit?
Does testing fit with other branches of science, such as computer science? James Bach, referring to Richard Feynman's definition of science as "the belief in the ignorance of experts," wrote in What Software Testing Is Really About, "It's more about science than it is about computer science."
Testers also believe in the ignorance of experts, yet software testing is given only minimal focus in computer science studies. Perhaps it's about time to explicitly and thoroughly include the science of software testing in computer science studies.
Test coverage is based on the science of the search space from evolutionary computational theory (refer Machine Nature by Moshe Sipper). How many test conditions are there and how many ways do they combine? Ask this question of every single specification and every single module and you have the total search space. Then, bearing in mind such constraints as time, money, and available resources; develop a test suite that provides an appropriate level of test coverage. Your project managers will most definitely advise you what they consider to be appropriate, but make sure they do so having first understood the total search space. A few laws or mechanisms can explain many complex phenomena.
Finally, is it all quantitative and expressible by mathematics? Probably, but I leave that one to the mathematicians amongst you! Certainly test metrics can be expressed quantitatively.
Overall then, I think theories about software and how well it is working can be tested scientifically and would meet most of Wolpert's additional criteria for science.
Testing As A Candle In The Dark
The late and great Carl Sagan sub-titled his marvelous 1997 book The Demon Haunted World with the provocative phrase "Science as a candle in the dark."
Software testing is unnatural to many developers. Some would even claim it unnecessary. Yet testing is a candle in the dark. Why? It's certainly not productive, in the sense that testers don't write specifications nor do they write code. This often fuels criticisms of testing as a profession. It's all seen as overhead costs.
Kaner, Bach, and Pettichord hit the nail on the head in Lessons Learned In Software Testing with Lesson 1: You are the headlights of the project. Why? Because "Testing is done to find information."
Without such information, projects operate in the dark. Ignorance is not bliss when your software is full of bugs and you think you're OK to deploy.
Projects need to embrace the unnatural nature of software testing; otherwise the great demons of ignorance and chaos (similar to Harry Robinson's recent StickyMinds original "The Demons Of Ambiguity") will descend upon them. Software that is not open to falsification is likely to be bad software. If it's really bad, then it becomes non-software, which is unwanted, unclean, and unfit for production. Yet good software, like a good scientific theory, can persist and is resilient. It's the survival of the fittest for both the software, and for the team of people that write and test it.
Good testers are born sceptics. By all means, listen carefully and respectfully to the business, to the analysts, to the developers, and to the project manager. Then doubt everything you are told about the product, and figure out the best and cheapest ways to falsify what you've been told. Look for inconsistencies in what you read, and what you hear. Be pragmatic. Figure out what information you can rely on, and what might be questionable.
It is science that enables a society to progress, by testing ideas and rejecting those that fail. Science leaves us with ideas that are useful and work. Computers reinforce the ability of science to do this. Software is not only tested using the scientific method, but well tested software is relied upon the world over by scientists in every field. Like Newton, we can all stand on the shoulders of giants if we take a scientific approach to software testing. Science can leave us with software that works.
Conclusion - A Memeplex for Testing
How does all this apply to my exploration of testing and the scientific method? Here's a thought provoking quote from Team C004367 at the Replicators.com website (from Evolution and Philosophy) about the nature of truth: "The scientific method is a set of memes that has evolved to become the predominant process by which scientific hypotheses are tested and evaluated. This method is the way in which science distinguishes true and false memes."
So according to this view, the search for truth is very black and white, very binary (which does not exclude a lot of grey on the journey).
With a nod to the Replicators team, and given that "a set of memes" is now more commonly known as a memeplex here is my definition of the software testing method:
The software testing method is a memeplex that has evolved to become the predominant process by which software hypotheses are tested and evaluated. This method is the way in which testing distinguishes true and false memes about software.
Given the binary nature of computers, this black and white view seems entirely appropriate. A bit is on or it is off. The same can be said for every other bit. A black and white photograph often contains shades of grey. However, closer inspection reveals black and white pixels, even for the supposedly grey parts. Thus, grey does not exist, only black and white. This is how test cases reveal the "truth" about software. Bit by bit, so to speak. See Table 1.
| Fail | Pass |
| Black | White |
| False | True |
| Zero | One |
| Off | On |
| Table 1 |
The hypothesis that the software works is nominally "true" only if the testers fail to disprove the hypothesis. Of course, the proof of the pudding is in the eating. As we all know, production will consume any unfit software that passed through inadequate or ineffective testing.
Testing is not rocket science, but it does bear a close resemblance to the way that science works. An understanding of science, and of the scientific method, is essential to an understanding of software testing and the methodology of testing. Use the scientific method and embrace apparently unnatural falsification as something natural and positive!

")

Lets Hang!