Summary
Joe Farah explains that to successfully build a software configuration management (SCM) process, you must have a solid understanding of the objects you need to manage and a good feel for what SCM is supposed to accomplish.Defining a Software Configuration Management Process to Improve Quality
articleBy
|
Having a process means having a repeatable series of actions. For example, what steps should you take when a problem report arrives? In this case, you should clarify the content, accept the problem, prioritize, and, if urgent, contact the software automation and technology team (SWAT). A process can guide you when you take action and when you reach decision points, like a critical problem report case. When the decisions can be automated based on available data and the tools and mechanisms are in place to support the actions, a well-defined process can lead to successful automation. When a process is automated, problems can be repeated and are much easier to diagnose and correct. As the problems are corrected, we attain higher quality.
Let's examine the following three steps that deal with process: defining the process, automating the process, and improving process quality.
Building a Software Configuration Management Process
To successfully build a software configuration management (SCM) process, you must have a solid understanding of the objects you need to manage and a good feel for what SCM is supposed to accomplish. If your focus is good version control and repeatable builds, you're heading in the right direction but falling short of meeting your requirements.
The goal of having an SCM process is to successfully deliver a software product to a customer or market in concordance with your business plan. This may mean little to a programmer, but the configuration management (CM) team’s decisions needs to take into account both the customer and the business case.
When you initiate SCM in your project as simply a version control and a repeatable build process, you may find that the bigger picture is harder to achieve, because the practices and tools used to support this limited view of SCM can hinder growth. For example, by selecting a version control tool that does not support change packages at its core, you may end up teaching developers that file versions are the key unit of product advances rather than change packages. Once the tool is engrained in the environment, it's not easy to change the tool or the practice without dealing with a lot of resistance.
Additionally, if you begin with a version control tool and then realize that you need problem tracking, activity/task management, requirements/test case management, and so forth, you are working on an add-on tools approach, and in this case, it's not easy to change the tool. Using add-on tools means there's more integration required (between tools), more administration (different tools), more difficulty upgrading (as an upgrade can easily break the integration glue), and so forth. This is a common problem when the approach is “tools first.”
To counter this, you must ensure that you understand your end-to-end process and the technology capabilities needed to support such a process up front. If you have flexible enough technology that supports an integrated process definition within a CM framework, “tools first” is not necessarily bad because the tools are helping you implement the process.However, in the more general case, I suggest the following steps:
1. Identify “first-order objects” and those that should be, such as change packages or updates.
In a typical SCM shop, the product team manages the following processes and items: problem reports, defects, and bugs; feature requests, requirements, and user stories; files and directories; file and directory branches; file and directory revisions and versions; change packages and updates; baselines; builds; test cases; and verification sessions and test results.
These “first-order objects” have properties that can be tracked. In subversion, files checked in through a commit are considered a “change package.” However, you can't attach a prerequisite to this “change package,” and you can't assign it a promotion status or link it to a problem report. A first-order object can be referenced, can reference other objects, can have a state-flow, and can have other data associated with it. An “update” in CM+ is an example of a change package that is a first-order object.
There are many additional first-order objects that you might consider tracking as well, including: CM users, customer requests and issues, customer sites, projects, portfolios, and contracts.
When considering using a specific tool, make sure that it can support these first-order objects as well as other items or processes that you may need to manage along the way.
2. Identify the various states of a given object as it moves through in its lifecycle.
Each object should have its own lifecycle. You need to know how the object begins, the states it moves through in its lifecycle, and where it ultimately ends up. In some cases, you might have different kinds of objects—for example, emergency problems may follow a different path than non-emergency problems.
A software update (i.e., change package) might go through the following states:
- Originated: Basic work intent traceable to specific problems, features, etc.
- Open: Some work or perhaps checkouts have been done against the update.
- Coded: The files modified for the update are in the repository but not finally checked in. They are shelved.
- Reviewed: The update has been peer reviewed with action items, but no full re-review is required.
- Submitted: The files have been submitted and committed to the repository and are checked in.
- Ready: The update is ready to go into the next integration build.
- Selected: The update has been selected to go into the next integration build.
- Tested: The system integration build containing the update has been successfully tested.
- VerTested: Full verification of the feature or problem implementation has been completed.
- Production: The changes applied by the update are in production use or at least available.
Although this is a successful path if you follow it straight through, you may come across some obstacles that prevent the success path from being followed. For example, the update may cause a compile error that forces it to be moved to a “failed” state or rolled back to “open.”
Here's a similar set of states for a build record, an object used to track the definition and progress of a formal software build:
- Open: The build record is being defined.
- Defined: The build record is fully defined.
- Compiled: The build has been successfully completed (compile/link).
- IntTested: A basic system integration test suite has confirmed the sanity of the build.
- VerTested: The build has completed its system verification.
- BetaTested: The build is deployed in some customer beta sites.
- Production: The build is ready for production use.
3. Identify transitions between the states.
Consider our build object and the fact that not all builds will make it all the way through. Although not every build is intended to go through production, for the most part, we still have straight-line transitions from one state to the next. Each transition has a set of properties, which include the following:
- Criteria: When to transition from one state to another
- Authority: Who is responsible for or allowed to perform the transition
- Rules: What rules can prevent the transition
- Triggers: What happens once the transition is completed
The build state might need to regress as well. For example, if the compile/link fails, it may go back to the "open" state to add or roll back some updates, or you may want to create a new build record altogether. At some point, the definition needs to be frozen, which is typically when it reaches the "compiler" and "IntTested" state or the equivalent.
The update object is even more complex. After being "reviewed," it may go back to the "open" state for additional work. If it causes the build to fail, it might be demoted from "selected" to "submitted," requiring more work or perhaps a companion update to make the change complete. You might also add or remove other states to closely reflect your actual process. In any case, you have the capability of tracking and managing the "change" in the form of an update object and its state-flow.
Putting it all together, we now have state-transition diagrams and properties for each first-order object. Even though we may understand these objects fairly well, as time goes on we may find that we need to add more states or transitions or modify the properties.
Figure 1 shows what a typical state-transition flow diagram for a problem report might look like. This example, taken from Neuma's CM+ (full disclosure: The product I'm responsible for developing), assigns a color to each state so that you can make sense of the data just by looking at the colors of the records.
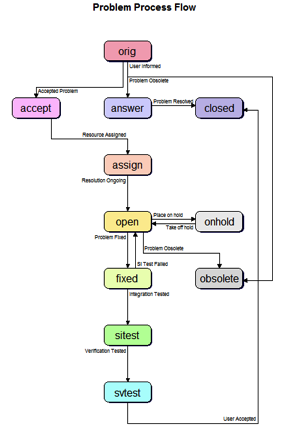
Figure 1. Problem Report State-flow diagram from CM+
4. Identify relationships between objects.
When we consider the broader impact of objects beyond their own individual state-flow, we are looking at a wider view of the process—the work flow.
When a build has been fully integration tested, the build record's updates (i.e., those updates referenced by the build record) should advance in status to indicate that they have been integration tested as well. In this case, a change of state to one object (e.g., the build record) should trigger a change of state to other objects (e.g., the updates). At the same time, any features referenced by the updates might be advanced to an "implemented" state indicating that the same features might appear on the verification team’s to-do list.
These are just a few examples of a work flow that goes beyond the object's own flow (i.e., state/transition flow). There are many such relationships in CM:
- A successful test case run indicates that the related requirements have passed
- The check-in of an update that references a problem report indicates the problem fix has been implemented
- The completion of a document review may cause a new feature to appear on a developer's to-do list
Workflow diagrams integrate the state flow with the inter-object flow that belongs with these relationships. You see the state flow, but you also see the side effects on other objects and their state flows. In the last example above, you may see the document moving through creation and review, but on the final review you'll see a feature assigned to a developer and then an update created to implement the feature, as well as test cases being developed to test the feature. The work flow links these objects (documents, feature, update, and test cases) and shows the bigger picture, whereas the update state-flow shows only how the update progresses.
For each transition of an object, you must ask, “As a result of this transition, who needs to do what?” Though specifics will differ from one organization to the next, a few examples might be as follows:
Feature specification completed and approved for release
- Feature appears on the developer or design manager to-do list
- Feature appears on the tester or test team to-do list for test case implementation
- Feature appears on the technical writer to-do list for feature documentation
Update checked in
- Run build to verify basic integration of update.
- Notify developers who were waiting to modify some of these files (if using exclusive checkout). Add update to the quality review to-do list.
Build approved for production
- Generate a new baseline definition for the production build.
- Ensure all affected updates have advanced to the production state.
- Generate "release notes" and send to the tech writer's to-do list for edits.
Whereas the state/transition flow dealt with the lifecycle of individual types of objects, these workflow relationships knit the objects together to form your complete SCM process, perhaps more accurately referred to as the application lifecycle management (ALM) process.Automating Your SCM Process
Now that your SCM process is well understood and well documented, it's time to automate. Automation is the key to creating a mature process because it allows you to attain high quality while at the same time freeing you up to advance your process further. There will be parts that are easy to automate, such as simple notification and cross-object work flow triggers; parts that are more difficult, such as nightly build automation; and parts that should not be automated. The latter category might include decisions to release a product, create a new baseline reference, or allocate developers to specific tasks.
Hit the easy targets first. What makes them easy depends largely on your technology. Some CM and ALM tools provide only a scripting language and a set of data access functions. Although the tools let you define your process, this is not an ideal situation because the process is hidden in scripts rather than being visible.
Some vendors give you not only a set of prewritten scripts but also documentation that reflects those scripts. Now that you have a process and a documentation method, you should ask yourself the following questions: How well does this process fit your project or organization? How much effort is it to change the scripts and documentation to match your preferred process?
Some tools have state-flow engines either as a third-party tool or an integrated component. Typically, there is some interface between this component or engine and your CM or ALM tool. This allows you to design the state flow and then use that definition to drive your scripts. An ideal tool has its state flow engine integrated into its behavior so that changing the state-transition flow for an object will immediately result in different behavior. This higher-level capability helps speed up automation.
The harder part of automation is the workflow, because any action can result in a set of other actions. Rules and triggers are used in most tools to help automate this workflow and are typically implemented in a scripting language. It is important to find tools with strong, data-centric scripting languages. For example, suppose you want to advance problem-report and feature states based on a successful integration build. The problems and features might move from a state of "open" to a state of "implemented" on the way to the next state, which might be "verified." In a second-generation tool, you might have a script that goes something like:
- Loop: Examine all file revisions to find ones with the specified build tag.
- For each file revision, identify the update or change package that created the file revision.
- Look at each of the updates to see if they reference any problems or features.
- For each of the problems or features, check for any other outstanding updates against them.
- If there are no outstanding updates and if the status is less than "implemented," advance the status to "implemented."
The above would be a list of high-level comments for the script, with the implementation a fair bit more detailed. Now, contrast this with a fourth-generation tool’s full script:
- change ((features of changes of <build>) where status < implemented) minus (features of all updates where status < submit) -field status -to implemented
- change ((problems of changes of <build>) where status < implemented) minus (problems of all updates where status < submit) -field status -to implemented
This example shows a more powerful, data-centric scripting capability that uses two relatively simple scripting lines to accomplish the required automation: The first advances feature status while the second advances problem status. The strong CM traceability integrated with advanced query and specification constructs can significantly reduce the scripting complexity. Some third- and fourth-generation tools also have common triggers that can be enabled by the click of a button.
For example, the properties of a transition on a state-flow diagram might pop up a dialog that allows you to enable automatic triggers when the transition occur. These might include options such as:
- [On transition of a problem to the fixed state] Send an email to the problem originator.
- [On check in of a design document] Send an email to all the reviewers.
- [On accepting a problem report as legitimate] log the date, time, and user
- [On any state change] Log the date, time, and user
Such tools can understand these sorts of special cases as common occurrences that are coded into a simple interface selection. Tools make a big difference in how easily the process can be automated. The goal is for you to automate everything that reasonably can be automated and to leave items on a prioritized to-do list for things that cannot be automated (e.g., performing peer review of code). In the end, you will have a process defined, automation whenever possible, and marching orders for things that require attention.
Building Quality into Your SCM Process
Your automated SCM process will have a lot of good things going for it, but it will also have problems, such as the following:
- The process breaks down when a key person is on vacation.
- The process needs to be modified when you comply with urgent requests.
- When you let developers request features, you may forget to run them by the customer.
The final step of process capability is to allow you to change your process dynamically so that you can respond in a timely manner to such problems as they crop up. By responding, you're improving the quality of your process. Like all changes, of course, process changes need careful review as well, but as you address these problems one by one, you really are maturing your process, resulting in a higher-quality product.
In order to build this level of maturity into your process, you need to be able to easily modify the process over time. This may involve several capabilities, including:
- The ability to add extra data or properties to describe objects (e.g., “These problems are on a gating list, preventing the release to production”). In some cases, this means adding data fields to your schema or allowing new values for existing fields. In others, it means ensuring that you can reference other objects from this object.
- Data-driven process is preferred over scripting, as it allows the process to be more clearly visible, which in turn allows changes to be less error prone and probably faster to implement
- Simplicity provided through higher-level scripting or even graphical configuration.
If you can quickly identify the cause of problems within your automated process and easily correct them, you're on your way to improving quality. This happens incrementally; a continuous improvement process.
In the End
After all is said and done, you can clearly define your process once you understand what you need to manage and you define the object flow for each object and the work flow across the entire ALM function. Advanced process tools that integrate with your CM or ALM function allow you to put your finger on the cause of each problem, thus making it much easier to improve quality.
Next-generation tools will speed your automation and improvement processes through their advanced capabilities and end-to-end integration of data and configuration tools. The benefits to your product will become obvious in short order, but the benefit in terms of team satisfaction will go beyond improved productivity, allowing team members to feel satisfied with their work.
About The Author

Community Sponsor



Not specified
Lets Hang!