In other words, this mess only happens when people are working in parallel. If we serialize the efforts of our team by never branching and never allowing two people to work on a module at the same time, we can avoid ever facing the need to merge two versions of a file.
However, we want our developers to work concurrently. Think of your team as a multithreaded piece of software, each developer running in its own thread. The key to high performance in a multithreaded system is to maximize concurrency. Our goal is to never have a thread which is blocked on some other thread.
So we embrace concurrent development, but the threading metaphor continues to apply. Multithreaded programming can sometimes be a little bit messy, and the same can be said of a multithreaded software team. There is a certain amount of overhead involved in things like synchronization and context switching. This overhead is inevitable. If your team is allowing concurrent development to happen, it will periodically face a situation where two versions of a file need to be merged into one.
In rare cases, the situation can be properly resolved by simply choosing one version of the file over the other. However, most of the time, we actually need to merge the two versions to create a new version.
What do we do about it?
Let's carefully state the problem as follows: We have two versions of a file, each of which was derived from the same common ancestor. We sometimes call this common ancestor the "original" file. Each of the other versions is merely the result of someone applying a set of changes to the original. What we want to create is a new version of the file which is conceptually equivalent to starting with the original and applying both sets of changes. We call this process "merging".
The difficulty of doing this merge varies greatly for different types of files. How would we perform a merge of two Excel spreadsheets? Two PNG images? Two files which have digital signatures? In the general case, the only way to merge two modified versions of a file is to have a very smart person carefully construct a new copy of the file which properly incorporates the correct elements from each of the other two.
However, in software and web development there is a special case which is very common. As luck would have it, most source code files are plain text files with an average of less than 80 characters per line. Merging files of this kind is vastly simpler than the general case. Many SCM tools contain special features to assist with this sort of a merge. In fact, in a majority of these cases, the two files can be automatically merged without requiring the manual effort of a developer.
An example
Let's call our two developers Jane and Joe. Both of them have retrieved version 4 of the same file and both of them are working on making changes to it.
One of these developers will checkin before the other one. Let's assume it is Jane who gets there first. When Jane tries to checkin her changes, nothing unusual will happen. The current version of the file is 4, and that was the version she had when she started making her changes. In other words, version 4 was her baseline for these changes. Since her baseline matches the current version, there is no merge necessary. Her changes are checked in, and a version of the file is created in the repository. After her checkin, the current version of the file is now 5.
The responsibility for merging is going to fall upon Joe. When he tries to checkin his changes, the SCM tool will protest. His baseline version is 4, but the current version in the repository is now 5. If Joe is allowed to checkin his version of the file, the changes made by Jane in version 5 will be lost. Therefore, Joe will not be allowed to checkin this file until he convinces the SCM tool that he has merged Jane's version 5 changes into his working copy of the file.
Vault reports this situation by setting the status on this file to be "Needs Merge", as shown in the screen dump below:
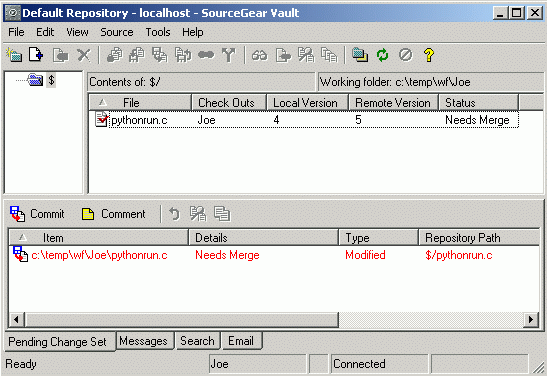
Best Practice: Keep the repository in sight
This example happens to involve the need to merge only a single checkin. Since Joe's baseline is 4 and the current repository version is 5, Joe is only 1 version out of date. If the repository version were 25 instead of 5, then Joe would be 21 versions out of date instead of just 1, but the technique is the same. No matter how old his baseline is, Joe still needs to retrieve the latest version and do a three-way merge. However, the older his baseline, the more likely he is to encounter conflicts in the merge.
Keep in touch with the repository. Update your working folder as often as you can without interrupting your own work. Commit your work to the repository as often as you can without breaking the build. It isn't wise to let the distance between your working folder and the repository grow too large.
In order to resolve this situation, Joe effectively needs to do a three-way comparison between the following three versions of the file:
- Version 4 (the baseline from which he and Jane both started)
- Version 5 (Jane's version)
- Joe's working file (containing his own changes)
Version 4 is the common ancestor for both Joe's version and Jane's version of the file. By running a diff between version 4 and version 5, Joe can see exactly what changes Jane made. He can use this information to apply those changes to his own version of the file. Once he has done so, he can credibly claim that his version is a merge of his changes and Jane's.
Strictly speaking, Joe is responsible for whatever changes Jane made, regardless of how difficult the merge may be. He must perform the changes to his file that Jane would have made if she has started with his file instead of with version 4. In theory, this could be very difficult:
- What happens if Jane changed some of the same lines that Joe changed, but in different ways?
- What happens if Jane's changes are functionally incompatible with Joe's?
- What happens if Jane made a change to a C# function which Joe has deleted?
- What happens if Jane changed 80 percent of the lines in the file?
- What happens if Jane and Joe each changed 80 percent of the lines in the file, but each did so for entirely different reasons?
- What happens if Jane's intent was not clear and she cannot be reached to ask questions?
All of these situations are possible, and all of them are Joe's responsibility. He must incorporate Jane's changes into his file before he can checkin a version 6.
In certain rare situations, Joe may examine Jane's changes and realize that his version needs nothing from Jane's version 5. Maybe Jane's change simply isn't relevant anymore. In these cases, the merge isn't needed, and Joe can simply declare the merge to be resolved without actually doing anything. This decision remains subject to Joe's judgment.
However, most of the time it will be necessary for the merge to actually happen. In these cases, Joe has the following options:
- Attempt to automerge
- Use a visual merge tool
- Redo one set of changes by hand
Each of these will be explained further in the sections below.
Attempt to automerge
As I mentioned above, a surprising number of cases can be easily handled automatically. Most source control tools include the ability to attempt an automatic merge. The algorithm uses all three of the involved versions of the file and attempts to safely produce a merged version.
Best Practice: Only use "automerge on get"
It is widely accepted that SCM tools should only attempt automerge on the "get" of a file. In other words, when Joe realizes that he must merge in the changes Jane made between version 4 and version 5, he will tell his SCM client application to "get" version 5 and attempt to automatically merge it into his working file. CVS, Subversion and Vault all function in this manner.
Unfortunately, SourceSafe attempts to "automerge on checkin". This is just a really bad idea. When Joe tries to checkin his changes, SourceSafe attempts the automerge. If it believes that it has succeeded, then his changes are checked in and version 6 was created. However, it is possible that Joe never examined version 6, or even compiled it. The repository now contains a file which has never existed in the working folder of any developer on earth. Its contents have never been seen by human eyes, and it has never been run through a compiler. Automerge is safe, but it's not that safe.
It is much better to "automerge on get". This way, the developer can (and should) examine the file after the automerge has happened. This simple change makes it easier to trust automerge. Instead of trying to do the developer's job, automerge simply becomes a tool which the developer can use to get his job done faster.
The reason that automerge is so safe in practice is that the algorithm is extremely conservative. Automerge will refuse to produce a merged version if Joe's changes and Jane's changes appear to be in conflict. In the most obvious case, if Joe and Jane both modified the same line, automerge will detect this "conflict" and refuse to proceed. In other cases, automerge may fail with conflicts if two changes are too close to each other.
Use a visual merge tool
In cases where automerge cannot automatically resolve conflicts, we can use a visual merge tool to make the job easier. These tools provide a visual display which shows all three files and highlights exactly what has changed. This makes it much easier for the developer to perform the merge, since she can zero in on the conflicts very quickly.
There are several excellent visual merge tools available, including Guiffy and Araxis Merge. The following screen dump is from "SourceGear DiffMerge", the visual merge tool which is included with Vault. (Please note sometimes I have to reduce the size of screen dumps to make them fit. In those cases, you can click on the image to see it at full resolution).

This picture is typical of other three-way visual merge applications. The left pane shows Jane's version of the file. The right pane shows Joe's version. The center pane shows the original file, the common ancestor from which they both started to make changes. As you can see, Jane and Joe have each inserted a one-line comment. By right-clicking on each change, the developer can choose whether to apply that change to the middle pane. In this example, the two changes don't conflict. There is no reason that the resulting file cannot incorporate both changes.
The following picture shows an example of changes which are conflicting.

Both Jane and Joe have tried to change the wording of this comment. In the original file, the word used in the comment was "Global". Jane decided to change this word to "Worldwide", but Joe has changed it to the word "Rampant". These two changes are conflicting, as indicated by the yellow background color being used to display them. Automerge cannot automatically handle cases like these. Only a human being can decide which change to keep.
The visual merge tool makes it easy to handle this situation. I can decide which change I want to keep and apply it to the center pane.
A visual merge tool can make file merging a lot easier by quickly showing the developer exactly what has changed and allowing him to specify which changes should be applied to get the final merged result.
However, as useful as these kinds of tools can be, they're not magic.
Redo one set of changes by hand
Some situations are so complicated that a visual merge tool just isn't very helpful. In the worst case scenario, Joe might have to manually redo one set of changes.
This situation recently happened here at SourceGear. We currently have Vault development happening in two separate branches:
- When we shipped version 2.0, we created a branch for maintenance of the 2.0 release. This is the tree where we develop minor bug fix releases like 2.0.1.
- Our "trunk" is the place where active development of the next major release is taking place.
Obviously we want any bug fixes that happen in the 2.0 branch to also happen in the trunk so that they can be included in our upcoming 2.1 release. We use Vault's "Merge Branches" command to migrate changes from one place to the other.
I will talk more about branching and merging in a later chapter. For now, suffice it to say that the merging of branches can create exactly the same kind of three-way merge situation that we've been discussing in this chapter.
In this case, we ended up with a very difficult merge in the sections of code that deal with logins.
In the 2.0 branch, we implemented a fix to prevent dictionary attacks on passwords. We considered this a bug fix, since it is related to the security of our product. In concept this change was simple. We simply block login for any account which is seeing too many failed login attempts. However, implementing this mini-feature required a surprising number of lines to be changed.
In the trunk, we added the ability for Vault to authenticate logins against Active Directory.
In other words, we made substantial changes to the login code in both these branches. When it came time to merge, the DiffMerge was extremely colorful.
In this case, it was actually simpler to just start with the trunk version and reimplement the dictionary attack code. This may seem crazy, but it's actually not that bad. Redoing the changes takes a lot less time than coding the feature the first time. We could still copy and paste code from the 2.0 version.
Getting back to the primary example, Joe has a choice to make. His current working file already contains his own set of changes. He could therefore choose to redo Jane's change starting with his current working file. The problem here is that he might not really know how. He might have no idea what Jane's approach was. Jane's office might be 10,000 miles away. Jane might have written a lousy comment explaining her checkin.
As an alternative, Joe could set aside his working file, start with the latest repository version and redo his own changes.
Bottom line: If a merge gets this bad, it takes some time and care to resolve it properly. Luckily, this situation doesn't happen very often.
Verifying the merge
Regardless of which of the above methods is used to complete the merge, it is highly recommended for Joe to verify the correctness of his work. Obviously he should check that the entire source tree still compiles. If a test suite is available, he should build and verify that the tests still pass.
After Joe has completed the merge and verified it, he can declare the merge to be "resolved", after which the SCM tool will allow him to checkin the file. In the case of Vault, this is done by using the Resolve Merge Status command, which explicitly tells the Vault client application that the merge is completed. At this time, Vault would change the baseline version number from 4 to 5, indicating that as far as anyone knows, Joe made his changes by starting with version 5 of the file, not with version 4.
Since his baseline version now matches the current version of the file, the Vault server will now allow Joe to do his checkin.
Worth the trouble
Best Practice: Give concurrent development a try
Many teams avoid all forms of concurrent development. Their entire team uses "checkout-edit-checkin" with exclusive locks, and they never branch.
For some small teams, this approach works just fine. However, the larger your team, the more frequently a developer becomes "blocked" by having to wait for someone else.
Modern source control systems are designed to make concurrent development easy. Give them a try.
I hope I have not scared you away from concurrent development by explaining the gory details of merging files. In fact, my goal is quite the opposite.
Remember that easily-resolved merges are the most common case. Automerge handles a large percentage of situations with no problems at all. A large percentage of the remaining cases can be easily handled with a visual merge tool. The difficult situations are rare, and can still be handled easily by a developer who is patient and careful.
Many software teams have discovered that the tradeoff here is worth the trouble. Concurrent development can bring substantial gains in the productivity of a team. The extra effort to deal with merge situations is usually a small price to pay.
Looking Ahead
In the next chapter I will be discussing the concept of a repository in a lot more detail.
Eric Sink is a software developer at SourceGearwho make source control (aka "version control", "SCM") tools for Windows developers. He founded the AbiWord project and was responsible for much of the original design and implementation. Prior to SourceGear, he was the Project Lead for the browser team at Spyglass (now OpenTV) who built the original versions of the browser you now know as "Internet Explorer". Eric received his B.S. in Computer Science from the University of Illinois at Urbana-Champaign. The title on Eric's business card says "Software Craftsman". You can Eric at


")

Lets Hang!