Summary
By incorporating SCM standards across database change management, developers gain security, and ease that was previously hard to come by. Tight deadlines are able to be met whether dealing with minor changes, or full-scale deployment and releases.
Applying Software Configuration Management Methodology to Database Development
articleBy
|
In the beginning, there was Chaos...
In the early days of software development, everyone did their own thing. Hardware was scarce and software projects were small. But soon, when multi-programmer projects became common, configuration- and change-control problems started rearing their ugly heads. When two programmers tried to edit the same source-code file, the inevitable happened and changes were over-written or lost. Initially, manual (human-based) change-control processes were instituted with varying degrees of success and varying degrees of overhead.
In order to solve the configuration-control problem, various software products and utilities attempting to address the problem were soon introduced:
- In the late 1950s, CDC introduced UPDATE, and IBM produced IEB_UPDATE - rudimentary tools to be certain, but they laid the ground-work for what was to come
- In the early 1970s, a Unix tool known as "make" was introduced
- Around 1972, Bell Labs introduced the original algorithm for "diff"
- In 1975, Mark Rochkind of Bell Labs wrote a paper for the IEEE which introduced SCCS, the first true source-code revision system (historical note: although the system itself is considered obsolete, it's file-formats endure to this very day in some modern SCM products)
- In the early 1980s, RCS was developed at Purdue University as a free (and open-source) alternative to SCCS. RCS is the direct predecessor to CVS and PRCS
- In 1985, Larry Wall (of Perl fame) introduced "patch"
- In 1986, Concurrent Version System (CVS) was created
- At the beginning of the new millennium, Subversion was released as well as viable distributed revision control systems like GNU "arch" and Bitkeeper
These products provided an evolution of functionalities and concepts that have moved the field of SCM forward in leaps and bounds.
In this paper, I will describe the concepts of the current solutions and propose requirements for a software solution that will extend SCM into the database configuration management realm.
SCM concepts
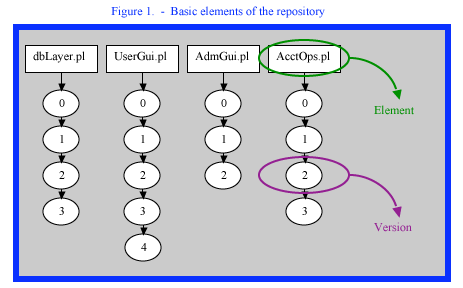
Element
An element is a file, directory or other entity under SCM control that allows the SCM to store version changes for that element. See Figure 1.
Version
A version is a specific iteration of an element. Versioning allows us to identify a timeline of changes to an element and gives us the ability to rollback changes to a specific version or point in time. See Figure 1.
Repository
The repository is a container of elements with all of their associated changes and versions. See Figure 1.
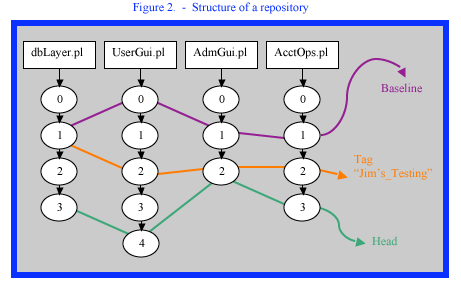
Baseline
A baseline is a collection of a single version of each element that together make up a known set configuration of the entire application (e.g. a GA release of the product). See Figure 2.
Tag
A collection of specific versions of certain elements. A Tag can be associated with a logical (human readable) name. Also called a Label. See Figure 2.
Head
The collection of the latest checked-in versions of every element in the repository. See Figure 2.
Check-Out
An action that reserves a specific (usually the latest) version of an element. This allows the user to then edit the source-code of the element. It also locks the element so other users cannot modify it. Usually, the user can add a comment describing the planned change to the check-out action.
Check-In
The opposite action to Check-Out. This returns the user's newly edited source-code to the repository (a new version is created) and unlocks it so other users may check-out. Usually, the user can add a comment describing what has been changed to the check-in action.
Rollback
The user may decide to back out of the change altogether. In such a case, a rollback action will be issued which will release the lock on the element. A new version may be created (implementation dependant).
Source Management Strategies
File-locking
This is the simplest strategy. When an element is checked-in, it is locked as read-only for all users. When a user checks-out an element, that element is locked in read-only mode for all other users until the original checking-out user performs a check-in or a rollback.
Version Merging
Many modern SCM tools allow multiple users to edit an element concurrently. The first user to "check-in" their changes will always succeed. All subsequent "check-in" actions on the same element will trigger a "merge" - the onus is on the user performing the "check-in" to ensure that their changes are merged with all previous users' changes and any conflicts are resolved.
A Glaring Omission - the database development environment
These Change-Management mechanisms have been around for a long time and the various strategies have proven to be very effective in allowing large teams to concurrently develop large software projects.
One discipline which has not been included in the automated handling of SCM operations is the management of database schema-objects and data. This arena is still a wild and hairy place where each organization must develop a set of manual (or semi-automated) policies and procedures to facilitate Database Change-Management of schema objects and data. Considering the strategic role databases play within organizations, one would assume the database development environment would be a highly focused area for disciplined SCM practices.
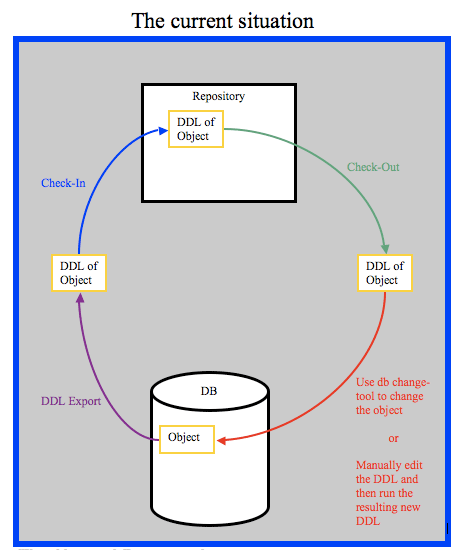
In most organizations, this involves exporting the DDL (Data Definition Language) of the schema-object to a text-file and then checking-in that file into the SCM. When a change needs to be made to a database element, the DDL is checked-out, edited in a text editor or database change tool, then the change is applied to the database, and then the new DDL is checked-in to SCM.
The challenge organizations face with the current situation is that there is a two-step process when checking-in and checking-out the database object DDL. This often leads to the wrong DDL being check-in or the wrong DDL being applied to the database. These issues can be worked-around procedurally, but they will always exist to some degree. There is no validation that the right DDL is being checked-in to SCM or applied to the database.
Also, the database object itself is never locked and can be changed at any time without a corresponding change in the DDL of the object that is stored in the repository. This can lead to discrepancies and loss of synchronization between the object in the database and the DDL in the repository. This change is also not logged or audited in any standard fashion, so repeatability, accountability and auditing are also hampered.
The Natural Progression
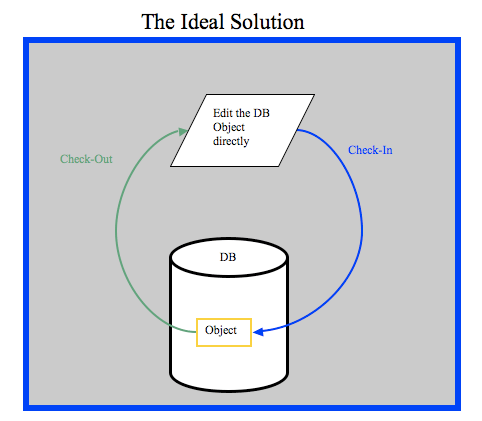
Database development needs to become an integral part of the disciplined SCM process, same as source code. With the ever increasing demand of doing more with less, tight deadlines, frequent business needs for application updates, code quality and compliance - which are all the reasons source code SCM was adopted at impressively high rates, database development is the next discipline for development VPs and Directors to concentrate on. There is a rewarding outcome for development organizations that treate both Database development and source code development equal from an SCM perspective.
Conclusion
Source-code developers have enjoyed the use of SCM facilities for over 20 years. It's time to bring Database Change Management processes up to modern SCM standards and allow database developers and DBAs to enjoy the same level of simplicity and process-security.
Integration with existing, traditional SCM products would facilitate a homogenous development process across source-code and database objects alike.
The database development community needs a solution that provides advantages such as object-locking and auditing that allow for tighter control of the development team's processes.
Such an approach would also facilitate change deployment and release management of database objects and schemas. Don't leave the database behind.
Tal Nizani is the Chief Technical Evangelist for dbMaestro LTD. Since 1995, Tal has been involved and led various large IT development projects primarily focused on the database environment (Oracle, MS-SQL, Sybase). Tal has also managed complex projects involving compliance and data security for multi-nationals. Tal can be contacted at [email protected]
About The Author

Community Sponsor

")

Not specified
Lets Hang!