This is the final part of a four-part series addressing software performance testing. The general outline of topics is as follows:
- Part 1
- - The role of the tester in the process
- - Understanding performance and business goals
- - How software performance testing fits into the development process
- Part 2
- - The system architecture and infrastructure
- - Selecting the types of tests to run
- Part 3
- - Understanding load (operational profiles OP)
- - Quantifying and defining measurements
- Part 4
- - Understanding tools
- - Executing the tests and reporting results
 Understanding Tools
Understanding Tools
As previously noted, tools provide answers to questions. The first parts of this paper addressed the problem of defining the questions to be asked of the tools and examined those elements of a performance test that need to be in place before you should even be concerned with tools. When we talk about performance tools, we are talking about three specific categories: load generators, end-to-end response time tools and monitors (probes).
A successful performance test requires all three types of tools, properly configured and working together.
Load-generation tools cannot measure true end-to-end timing of a user experience, as they use virtual users or clients and do not include the workstation overhead in their measurements. If the user experience is critical-heavy graphics usage, large amount of business logic on the client (fat versus thin)-then an end-to-end tool is essential.
Monitors (probes) are essential to solving any performance problems that may be identified during the testing. Performance refers to how something behaves (performs) under a defined set of circumstances. When running a test, measures have to be taken in many areas: memory, CPU, threads, network statistics, database measures, internal application measures, etc. These measures may have to be taken from several platforms or servers depending on the type of application under test.
Getting the right set of tools is essential to a successful test. The combined tool set provides the tester with an answer.
When looking at load generation, there are multiple possibilities:
- Generate the load manually employing actual users
- Build your own tool
- Purchase or lease a load tool
- Use a third-party application service provider (ASP)
Manual generation of load is probably not going to work very well. Unlike tools, real people get bored, tired, and distracted from the task at hand. Although some types of tests-such as a sudden ramp-up of users-are possible using this method, the results are generally not very reliable. Employing actual users also may have a scaling problem; there are only so many people available and so many workstations. Tests to stress the system beyond normal limits may be impossible. It can also be very expensive to bring in a sufficient number of people, usually on a weekend, to generate the necessary volume of activity for the test.
Building your own tool is sometimes the only possible choice. The majority of commercial tool vendors focus their tools on specific areas of the market, preferably an area with many possible clients. As such, there may not be any commercial tools available for the architecture or infrastructure on which you are testing.
There are advantages and disadvantages to building your own performance tools, as shown in table 1.
Advantages | Disadvantages |
It
will function in your environment | It takes time to engineer
and create the tool |
It
will contain the features you require | The tool will require
initial testing to ensure it functions as expected |
It
can be modified to provide all necessary trace and internal measure
information as the architecture changes | Once built, the tool has to be
maintained internally. All new functions have to be created |
Table 1
Purchasing or leasing a tool or a combination of the two is the most common approach to acquiring load-generation tools. For smaller applications or systems, the purchase of a tool can be effective. However, as the number of users to be simulated increases, the additional cost of tool licenses increases-as well as the hardware and infrastructure required to support the load generator.
The final possibility is to outsource the performance testing to an ASP specializing in performance testing. The advantages are that these vendors typically have access to the necessary infrastructure and tools. The disadvantage is that they still have to obtain the same information as an in-house performance team. To properly leverage an ASP, all the initial work on defining goals, load profiles, etc. noted in previous sections should be completed before a contract is signed.
Regardless of the method used, utilizing the maximum number of virtual clients or events that a performance testing tool license allows may not actually generate the greatest load. Depending on the capacity of the load-generating machine, the load generator may be wasting too much time juggling the various virtual clients or events in and out of memory instead of actually processing their requests. At some point, as more virtual events or users are added, they may, in fact, slow down the total number of requests that are being submitted, as shown in figure 1.
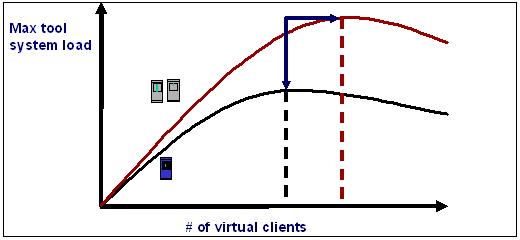
Figure 1
Before conducting any server measurements, it is important to calibrate the load generators to determine what percentage of degradation will be attributable to the load generators' being stressed and at what point the load generators max out.
Since each virtual client requires resources, when selecting a performance testing tool, find out what the resource requirements are for each virtual user. For example, if each virtual client needs 2 MB of RAM and you have four test PCs, each with 64 MB of available RAM (4 x 64 / 2 = 128), a maximum of 128 virtual clients may not be enough if you are expecting several thousand concurrent users.
Factors affecting the amount of resources each virtual client needs include:
- Size of the test script being executed
- Virtual storage used by the script
- Resources used such as threads, etc.
Creating the correct distribution of user activities in the tool is also critical to proper load generation and is critical to avoiding problems that can over-enhance or degrade performance. Factors that can affect load distribution include:
- How the load mix is defined to the tool
- How the tool handles think times
- How the tool starts the load
- How the tool increments the load
- How the tool records and manages session ids and cookies
- How the tool handles re-execution of the scripts and virtual clients
- How the repetitions are treated (new users or the same user?)
- This can affect concurrent user counts, etc.
Some performance testing tools allow multiple threads per virtual client, thereby making the load more realistic and increasing the load on the server. Another feature that some performance testing tools offer is the ability to run each virtual client in its own process. One virtual client per process can be extremely demanding upon the load generators, but may make the load more realistic. For larger loads, it becomes particularly convenient if the load generators can all be coordinated via a single console-a feature provided by most commercial tools.
Where and how the load is applied to the network also is a critical decision. If you have a network with security features and you place the load internal to the network, you are leaving out the security mechanism and possibly the service connection.
To apply the load outside the network requires access to proper network resources to generate sufficient load for all types of test types, but especially for stressing the connection and the security apparatus. Some tools use methods such as IP spoofing to make the load more realistic. This can be a problem with some security elements (firewalls) as they are designed to prevent spoofed IPs from accessing the system. Careful coordination with the security personnel is essential.
Load tools can also use agents placed around a network to better simulate the distribution of activity over the network. Agents need to communicate with the main tool control host (console). This communication consumes some network resources so care must be taken in the application of the load. With a segmented LAN/WAN ask yourself:
- Do you test on only one segment or location?
- To test multiple points you may need agents for the load generator, will these affect the test (they use network resources)?
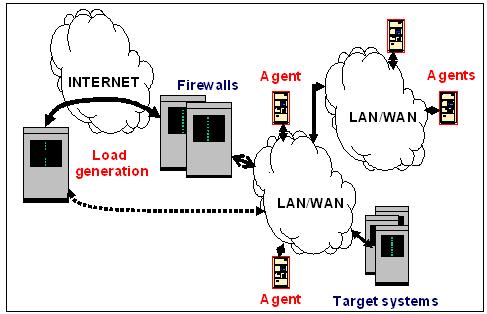
Figure 2
Figure 2 shows the application of load to a networked environment.
Executing Tests and Reporting Results
The last part of performance testing is execution and reporting. Too often we over focus on the tools and the data they provide. Execution and reporting are the "last" issues to address, not the first.
If the planning, analysis and design of the performance testing went well, execution becomes a straightforward process. We should now have a good idea of what we are trying to accomplish and where we think potential problems exist. Prior to executing the performance test, there are a few things we need to check.
- Is the test lab equipment set up and ready?
- This includes having the technical staff up to speed on any new equipment,
etc.
- Are the tools installed and calibrated?
- Have the scripts been created and the data sources set-up and synchronized?
- Are all the clocks on the various components synchronized, especially if multiple time zones are involved?
- All monitors must be active and running prior to the execution of the load test and probing clients.
- Notify people of the test start and end.
- During the test, the system cannot be used by unknown sources.
Test execution is not a single event. There are three stages that test execution typically goes through. The first stage is for correcting errors in the test scripts, environment, etc. Several sequences of tests may be required just to get the bugs out of the scripts. Script debugging is critical to avoid reporting false information. The initial set of tests, once debugged, can also be used for a smoke test. The second sequence of tests is used to tune and fix the system, application, network, etc. And the final stage is where you run the test with the intent of reporting the end results.
Resource monitoring occurs at every stage of the tests so that the information can be used to correct any problems and also to document progress. Depending on many factors-size of application, complexity of functions, stability of the system, availability and usability of tools, etc.-the number of runs at each stage will vary.
Performance test execution typically goes through three stages, as can be seen in Figure 3.
- In the first series of tests, the scripts are debugged and the characteristics of the tools are assessed.
- The second series of tests are the ones that assess the system and serve as the basis for tuning and debugging the system.
- The final series of tests are the ones we use to report results. The final tests should be run a minimum of three times to ensure consistency in the results.

Figure 3
Once the bugs are out of the scripts, we need to run the remaining tests. What we run depends on what types of tests we selected earlier and what the overall goals and objectives of the performance are. The number of test runs and the combinations of test types will depend on the tool in use and its capabilities.
Prior to running large, complex tests, it is important to check to see if the application is truly ready for extensive performance testing. If you have a simple application with only a few users and processes, a performance test may be a waste of effort. For a typical application involving dozens, hundreds, or even thousands of users, processes, and activities, the system becomes more complicated and time consuming, meaning plenty of things can easily go wrong. Therefore, before investing a large amount of time and effort into testing the performance of an application, it often pays to run a smoke test to determine whether more extensive testing is warranted and if the application is ready.
Smoke tests can be as simple as performing a few manual (single-shot) tests with a stopwatch to running a fully automated suite of tests that execute a performance (and functional) regression test of the entire application. These smoke tests can then be used as an entry criterion for performance testing by the testing team.
Caution should be used in a single user test, as the initial results may not be the optimum. I use a simple process for smoke testing:
- Identify all transactions to be part of the performance test.
- Create three scripts for each transaction
- One using low-end field values
- One using high-end field values
- One using middle field values
- Run a test using one user with all transactions.
- Run a test with two to three users with all transactions.
- This will help verify system stability as well as transaction readiness.
This is just one of many possible entry criteria for performance testing. The key is to be sure the system is ready for extensive, heavy testing before you expend the resources. If the system is not stable and useful, then the results from the test may be worthless or, worse, misleading.
The high-value, low-value tests are based on the concept of equivalence partitioning and boundary analysis. By exercising transactions at their extremes, we can be sure that the general functionality of the application is intact and will not affect performance characteristics.
If the development team is using an incremental or iterative approach to application development, a smoke test can be incrementally built and applied to each increment.
Test execution will be controlled by the capabilities of the load-generation tool selected for the test. Each type of test selected earlier can be run as an individual test:
- An average load test
- A ramp-up test
- A stress test
- Etc.
For some tests, we may want to run a series of tests to see how the system reacts. For a usage test using average load, a slow incremental approach can be best:
- Start with one-third average expected load.
- Ramp the tool up to the next third.
- Finally, reach average.
- Allow the test to run for the specified measurement period.
Some bottlenecks occur at low volume, and too fast of an increase can hide the cause. If you can cause performance problems with a limited number of features and a small number of users (virtual users), you don't need the entire system or application in place. This is another reason to use an overlapping function and performance model for performance testing. Under this process, the scripts may need to be more flexible than if a single login or rendezvous checkpoint is used in the test prior to execution. I find this approach uncovers some types of problems easier than if a large number of users are running.
If the results of the usage-based tests using typical or average load are acceptable, other types of tests now can be run. It will be necessary to restore the environment prior to the next set of tests, as the tests will have altered the database. What other types of test we execute will depend on what we defined at the early stages of the planning process.
- Stress tests
- Busy hour (1.6x average) or other defined value
- Busy five minutes (4x average) an extreme peak
- Bounce and load variation tests
- Breakpoint tests
For stress types of tests, it is best not to try to push too fast. If there is a problem, you may pass the critical point before you realize it and may end up obscuring the critical data. The higher you push volume, the more repeatable the scripts need to be as well.
Before the actual test starts, be sure that you have started all monitoring processes and tools, especially those on the servers and network. Once the load has stabilized, notify those who will be doing or monitoring the response time processes.
Depending on the load tool capabilities, a series of several test types can be run. After the initial load is generated-usually the average load-you can increment the load up to other factors to stress the system at various loads. This can be done as a single test using a series of increments. I typically use this approach for the final sequence of tests that will be used for reporting results.
For example, a single load test may incorporate several different increments in single run. Many load tools allow you to select an initial load level, a ramp up factor, time duration to run the load increment, a scaling factor for the next increment, and a total duration time.
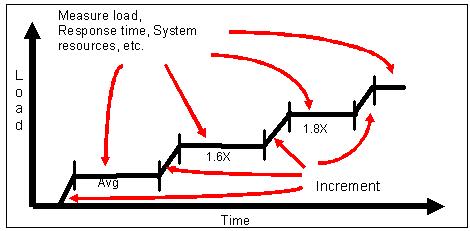
Figure 4
When the load has stabilized for each increment, you can gather the response time measures as well as other system measures, as shown in figure 4. It is critical that all resource monitors and the response-time process coordinate their times with the load in order to ensure that the correct measurements are generated. Measuring during the ramp-up and ramp-down times can alter the results. The test team has to decide whether to include these measures.
Once the test run has finished, be sure to wrap up, including the following:
- Stop the test if not automatic.
- Advise all team members of end of test.
- Stop the monitoring tools.
- Archive results from test tools, monitoring tools and instrumentation. Check twice that results are saved.
Depending on what was defined at the initial requirements stage, the performance report needs to show:
- Tests that were executed
- Loads and mixes were used for each test type
- The internal (white box) and external (black box) measurements that were collected
- Identification of potential problem areas.
- Testers identify problems, they do not correct them. That's why technical people must be part of the team
All output from the tools must be gathered and reported together. Most commercial tools have some reporting capabilities. Some can only show the data they gathered, others can integrate data from several sources. Reporting is a capability that should be investigated prior to the purchase of a tool. Many tools allow the data collected to be exported to Excel to generate graphs. Be wary of reporting early results: If the results from early testing appear to be too good to be true, investigate before reporting to ensure they are accurate.
All the relevant data sources need to be brought together for reporting:
- Data from the load tool
- Data from all relevant monitors
- Data from any probing tool
- This is why clocks must by synchronized
Ideally, run the final set of test loads for each test type several times before reporting "final" results. If the test was set up correctly, there will be some variance in each execution. This is exactly what we would expect if the load generator is properly executing the operational profile we defined.
No two runs of a test type should ever be identical. One of the primary goals of a performance test is to model or mimic the real world. The real world is "chaos"-every day, every hour, every session is different each time it occurs. Our load test needs to create this same type of chaos. Therefore, we run the final tests three to five times and average the results. This helps ensures consistency and accuracy in the test results.
I have found that the first time you attempt to build a software performance test it can take anywhere from six to sixteen weeks. This may seem like a long time, but we are dealing with calendar time, not 24/7, full-time involvement. There are natural delays between activities that make this happen. For example, when creating an operational profile it may take several days for the groups providing the data for analysis to get the data together. These delays occur at several points in the process and are normal.
There are many details and issues this series of articles did not address. The goal was to provide an understanding of the basic problems and complexities involved in building a successful software performance test.
Read "Understanding Software Performance Testing" Part 1 of 4.
Read "Understanding Software Performance Testing" Part 2 of 4.
Read "Understanding Software Performance Testing" Part 3 of 4.
Read "Understanding Software Performance Testing" Part 4 of 4.



")

Lets Hang!