Summary
Test data is one of the major bottlenecks in testing processes. By simplifying test data, we can solve this bottleneck by tackling four major challenges.
Test data is one of the major bottlenecks in testing processes. By simplifying test data, we can solve this bottleneck by tackling four major challenges.
In many organizations we see test data as one of the main bottlenecks in the testing process when trying to implement CI/CD, Agile, Test Automation, etc. A lot of time is lost finding the right test data cases, multiple teams are working on the same databases (with the attending consequences), time is wasted on making – and waiting for – full size copies and all of this slows down your testing efforts, not to mention the frustration and irritation it causes. If you want to know how you can solve this test data bottleneck, read on.
Back to the Basics
During the height of the space race in the 1960s, NASA scientists realized that pens could not function in space. They needed to figure out another way for the astronauts to write things down. So, they spent years and millions of taxpayer dollars to develop a pen that could put ink to paper without gravity. But their crafty Soviet counterparts, so the story goes, simply handed their cosmonauts pencils.
What if we looked at test data from this perspective? Get back to the basics and strive for simplicity! We need to create a simple solution in the complex world of test data. How can test data be made readily accessible? How can it be easily refreshed? How can you make it available whenever and wherever you want or need it? Imagine how much better your testing world would be if we had answers to these questions.
Let’s start with the reasons why test data isn’t readily accessible and available. If we zoom out for a moment, we basically see four major challenges causing the bottleneck:
1. Time
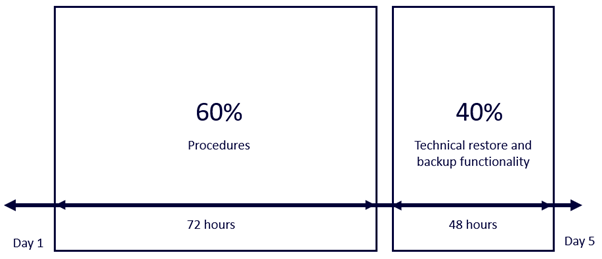
If you take a closer look at why test data takes so long to be refreshed, you discover this is partly technical and partly procedural. Research shows us that getting the right test data can take up to five working days. We’ve even come across organizations where it takes weeks! It’s interesting to find the reasons for these long waiting times.
On a technical level, the part of creating a backup and restoring it to a QA or other non-production environment takes time. It differs from minutes to hours to days, obviously dependent upon the size of the database and the larger the database is, the more time it takes. But the technicality of these procedures, the backup and restore, is unlikely to take longer than two days. Why? Because the traditional aim is to get it done over a weekend.
So at least 60% of our time is wasted on procedures before (or sometimes after) the technical execution. One of the major issues in these procedures is the fact that software testing teams aren’t allowed anywhere near the copy/backup and restore functions – that’s exclusively the domain of the DBA function. Therefore, these software quality teams are directly dependent upon other teams in the organization.
The Burden of a Request
The process of procedures you’ll have to take as an engineer probably looks something like:
Helping test teams with test data, in other words copying data from production to QA, isn’t the core part of a DBA’s job. As well as managing the availability and performance of the production environments there’s also the responsibility for capacity planning, installation, configuration, database design, migration, performance monitoring, security, troubleshooting and so on. DBAs constantly prioritize and review their own backlog and creating or refreshing a new QA database is probably not the highest priority task. As a result it may be awhile before you receive your test database.
Disturbing the DBA
Are we afraid to ask for a test database? If so, why? Well, because we know we are disturbing our DBA with a task that keeps them from doing what he or she is supposed to do. They won’t jump out of their seat with joy because the test function asks for a copy of production. On the other hand, a DBA wants to control this process. They won’t let you do it yourself since they’re the one responsible. But how do we not disturb the DBA?
Eliminating or automating these processes saves tremendous amounts of waiting time. Databases can be easily refreshed by setting up a system that automatically replenishes databases to the lower environment(s). This process can be achieved by talking to, and developing a solution with, the DBA team. If you eliminate these procedures a lot of problems are solved. You can start your automated tests or you start testing manually with your refreshed data.
2. People
So you have your test database and you execute some tests. But then you get a call from another test team: “What the @$*# are you doing?! You just destroyed all of my test cases!” Oops. This is another part of the test data bottleneck: people. Well, people themselves (in most cases) are not the problem but accommodating multiple teams or people on the same test databases is the problem.
3. Size
In the end the challenge is mostly caused by size and scale of the data stores. Let’s be honest, databases are backed up often and regularly. It’s a necessity in support of business continuity. The challenge of size is two-fold. First, it’s the number of bytes which must stream from the backup to the database in the lower environment combined with the speed and bandwidth of the I/O subsystem performing the task. Volume and time. The second issue brought about by size is space. The storage space required to hold, typically, three to five copies of the (full-size) production space. For space read money. More on that later.
Copies of Production
Time is a valuable asset in software development. Many organizations try to create an environment in which updates to software applications can be delivered every day, sometimes multiple times during the day. That’s why we try to implement CI/CD, Agile, Test Automation. We’re not only trying to save time but also to achieve a higher level of quality and adding value to the business in the enhancements we deliver.
Because of the size and time issues, test engineers start asking themselves the question “Do we really need a full copy of production?” In some cases the answer to this question is “No!”. What we then typically see is that they start generating test data themselves. Why? Because with this generated data they perceive that they can get started faster. Understandable but a little naïve…
Generating synthetic test data from scratch is a risk since it is not truly representative of the production environment. It would be very valuable for projects to have access to test data that could really represent production data. We need to encompass the data anomalies that exist in production as well as the pure test cases.
Test Data Coverage
There are multiple methods and techniques involved in deploying test data:
If you take a look at what coverage test data can have in these techniques you end up with a maturity model like this:
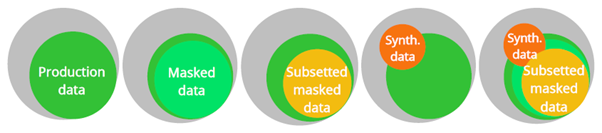
As we can see all test data other than production data loses a bit of “test coverage”. You can have masked data, but you lose a little bit of data representation. Arguably, synthetic data and AI data are the worst test data sets. It is often presented as the holy grail but what we have seen so far is that it is useless in a real project. You have no idea what data is in there. How do you therefore instrument your test?
From a business risk perspective, working with the most representative test data is the correspondingly most valuable approach. So working with production data or subsets of production data, either masked or not, is probably the best you can get. So to solve this part of the bottleneck, we start creating database subsets. This results in faster deployment, significantly saving time and addressing the size and space issues.
4. Money
With reducing the size of the test data we automatically start to solve the last part of the test data bottleneck: money. The two are inextricably linked. Provisioning copies of databases has a per megabyte/gigabyte cost regardless of whether we’re deployed on-premise or in-cloud. Again, remember the point made earlier that we often see three to five copies of production databases in the lower environment(s). The prime directive is to work within budgets and the smart approach is to maximize the benefit of the resources which the budget delivers us.
Conclusion
By tackling the four challenges ‘time’, ‘people’, ‘size’ and ‘money’, we solve the test data bottleneck. Yes, we can have copies of the database for each team – but they are smaller. Yes, we can move towards deploying these databases on a self-service or automated basis, relieving the DBA function of the task. Yes, we can reduce the downtime associated with refreshing an environment. Yes, we reduce the impact of a refresh across the teams. Yes, we can make the most of our budget.

1 comments

During the height of the space race in the 1960s, NASA scientists realized that pens could not function in space. They needed to figure out another way for the astronauts to write things down. So, they spent years and millions of taxpayer dollars to develop a pen that could put ink to paper without gravity. But their crafty Soviet counterparts, so the story goes, simply handed their cosmonauts pencils.
That's how the story goes. The trouble is that the story isn't true.
https://www.snopes.com/fact-check/the-write-stuff/
Research shows us that getting the right test data can take up to five working days.
What research is that?
We’ve even come across organizations where it takes weeks!
That suggests that the research is wrong, or incomplete.
Here's the main thing, though: testing begins and ends with models; representations of complex things in terms of simpler things. The data that we use in testing is a representation of the data that the system may encounter in production. So it would be helpful to frame our thinking about data in terms of several dimensions:
Notice that production data might not represent any of these things except the first. For that reason, when there's risk, data can and should be crafted to address the other points.
The good news is that none of this needs to be a bottleneck. Strategy can help us to set our targets; and tools can aid in generating the data that we need to identify problems and risks.
Lets Hang!