Summary
Testing continuous technological change can seem like chaos. There are many challenges that need to be managed, such as unavailability of power, excessive temperature, incorrect configuration, unexpected behavior of services, network downtime, and processing slowdown in production. By deliberately engineering chaos, we’ll be able to discover many of our systems’ weaknesses before our users do.Strengthening System Resilience with Chaos Engineering
articleBy
|
Testing continuous technological change can seem like chaos. There are many challenges that need to be managed, such as unavailability of power, excessive temperature, incorrect configuration, unexpected behavior of services, network downtime, and processing slowdown in production. In order to deal with these issues, we must proactively perform chaos engineering.
Chaos engineering is all about breaking the system on purpose so we can find out its weaknesses and fix them before they occur when least expected. It is a proactive approach to handle any failures and provide continuity of service under a degraded mode of operations. It helps us explore the unpredictable things that can happen so that we can then test and, ultimately, prevent them.
Testers have been doing this for a while, but Netflix formalized the approach. In Principles of Chaos Engineering, Netflix describes it as “the discipline of experimenting on a system in order to build confidence in the system’s capability to withstand turbulent conditions in production.”
Chaos engineering:
- Checks the system’s reliability, stability, and capability of surviving against unstable and unexpected conditions
- Provides seamless service in a distributed or cloud computing environment
- Simulates the production environment with various failure scenarios
- Improves the resilience of the system
- Is proactive in nature, as opposed to the reactive nature of traditional testing
By uncovering the vulnerabilities of the system, you expose hidden threats and minimize system risks, so the system is ultimately able to recover without impacting end-users.
Testing System Resilience
System resiliency is a measure of the ability of the system to automatically recover from problems that might otherwise cause it to fail, such as power outages, network failures, and invalid configuration. System resiliency is usually provided by redundancies and automatic rerouting of operations within the system.
We can implement chaos engineering and induce a defect to ensure that the system recovers gracefully, validating its resiliency. This helps us check that every component within an infrastructure provides consistent performance and reliability with varied conditions.
Start with a single component of software or infrastructure, then gradually include other dependent components. Identify all failure points in both internal and external components and interfaces based on the framework, then perform analysis on the scenarios.
There are some key strategies for testing resilient systems:
- Validate all failures, timeouts, or alternative available paths
- Validate application and data availability, and that you can use the backed-up data
- Validate all networks are available and there is no data loss due to latency
- Validate application available in case there is loss of a configuration file or a change of configuration
- Validate automated roll-forward and rollback mechanisms for the application
Requirements to Measure
Chaos engineering measures reliability, maintainability, and availability metrics while injecting possible failures at infrastructure, application, and network levels. A framework for key requirements and identification of scenarios should include at least these factors.
Fault injection is what it sounds like: testers introduce faults into the code on purpose to see how systems behave when stressed in unusual ways. This technique is based on simulation, so it may be closer to reality than using statistical methods.
Reliability is typically measured by the consistency of outcomes. A test is reliable if we get the same result repeatedly. We’re testing that software will not wear out during its lifecycle or change over time unless intentionally altered or upgraded.
Software flexibility normally refers to the ability for the solution to adapt to future changes in its requirements. Examples include a highly scalable architecture that can have capacity added with an increase in users, or a configurable database that can be enhanced with custom fields defined by the users of the system. Flexible systems have loosely coupled components such as a microservices-based architecture.
Availability is defined by the proportion of time a system is in a functioning condition. If a system is down 18.26 days of the year, that works out to 95% availability. High-availability applications are sometimes measured in a metric known as “nines,” corresponding to the number of nines in the percentage of uptime—so a service delivered without interruption 99.99% of the time would have four nines reliability.
There are some key chaos engineering requirements for an application:
- Under load with low memory and CPU, the output result should be consistent and there should be no degradation of response time
- Consistent error messages should be generated for uniform input data types
- The application must fail over to a secondary server when the primary server goes down
- The application must fail back to the primary server when a secondary server goes down
- The application must fail back to the primary server when it recovers from any fault
- There should be no data loss during a failover or failback
- The application should always be available during a failover or failback
A Framework for Identifying Scenarios
This chaos engineering framework is based on the number of locations (nodes or vertices) and links, also called connections. The network consists of nodes that are joined by links. A complete network has paths from each node to all other nodes. As the number of locations increases, the number of combinations doubles; as the number of levels in a distributed deployment increases, the combinations also increase.
For example:
Level 0 = Load balancer (one)
Level 1 = Application server (two primary and secondary)
Level 2 = Database server (two primary and secondary)
Let’s look at some typical application resilience scenarios and known sets of test combinations.
A typical distributed deployment of two levels with three nodes and three connections, represented by Location A below, would require at least four use case scenarios.
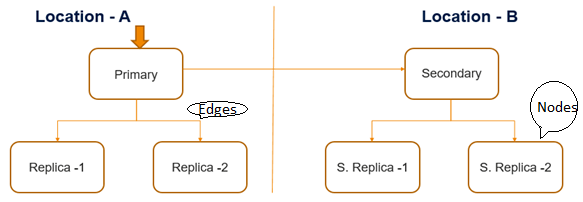
These four unique paths are:
- Replica 1 is down and Replica 2 is up
- Replica 2 is down and Replica 1 is up
- Both replicas are down
- The primary server is down
We could identify at least four use case scenarios of power failure, network failure, and configuration failure, where each failure is injected into the system. Based on this, we could derive the total number of test cases needed to test the system and the time required to validate this setup.
With an increase in distributed deployment to Location B, it would double the unique test scenarios. With an increase in levels of deployment, or more application tiers, the number of scenarios would increase in multiples of the levels. As the number of levels and nodes increase, this combination increases as well, leading to a setup that is difficult to validate manually. More things can go wrong, requiring more time to recover those services.
In a three-level deployment, there are 15 or 16 different sets of combinations that can be validated, including:
- Number of transactions failed or lost during failover
- Time taken to simulate the node going down and coming up
- Time taken to replicate the data from one node to another
- Type of error messages when one node is down or one location is down
This process normally starts small with an application, then slowly expands to the network and Infrastructure levels. After achieving successes and realizing the desired benefits, it can be scaled across the data center.
The table below shows some of the top 10 failures, which includes one failure causing other cascading failures (which makes the sum of all failures greater than 100%).
Activity causing a failure | Frequency |
Starting any or all application services | 60% |
In most scenarios, a specific combination and sequence of multiple events are required to simulate system failures. Thus, to expose as many failures as possible, we need to explore not only multiple combinations of event failures, but also different permutations of those failures. To simulate systems running at the appropriate intensity requires continuous long-running systems, with traffic like the actual load in production, using load tests running for more than four hours or doing a complete soak test.
Performance Simulation Complements Chaos Engineering
We should be able to break services or induce failures in production with the assumption that the system will recover without affecting end-users. However, because system downtime is not an option that any customer would accept, our main challenge is how to measure the outcomes of our chaos engineering in a production environment.
For example, because traffic is uncontrolled in production, there can be a variable number of requests per hour, so there would be no consistency in metrics to measure any loss due to downtime from induced failures. We need an approach to simulate high traffic in a pre-live environment rather than in our production environment.
In order to get an initial baseline of the system behavior, we run a load test with a typical load for a certain number of hours and identify the average transactions passed. Then we simulate the same load test with normal load (same number of users, workload mix, script settings, test data, and duration) but with expected disruptions like power, network, and application failures, and then collect the number of transactions passed and failed. Then compare the difference in number of transactions passed in the two tests, and that would give you the calculated availability of the application under test in the pre-live environment.
It is recommended to have automated tools that will inject failures systematically or randomly, so that you can efficiently and effortlessly simulate failures while performance testing the pre-live environment. This process also can be used to verify fixes and changes to the services by running random failure scenarios on a schedule in the pre-live environment.
Chaos is inevitable in our software systems. But by deliberating engineering chaos during our testing, we’ll be able to discover many of our systems’ weaknesses before our users do.
About The Author

Community Sponsor





Not specified
Lets Hang!