Summary
Matthew Heusser goes beyond trivial examples to talk about the tradeoffs and ancillary benefits of a large-scale acceptance check automation strategy.
Matthew Heusser goes beyond trivial examples to talk about the tradeoffs and ancillary benefits of a large-scale acceptance check automation strategy.
I previously introduced a long-term acceptance checking strategy that I have been using with a couple of teams for an extended period of time. In this article, I will catch up with that strategy two years into its operation.
Picture yourself on site with the client, reviewing the list of checks that run in every build. One day, you find something like the test run in figure 1, which is the output from one particular check.
The tool we used is called
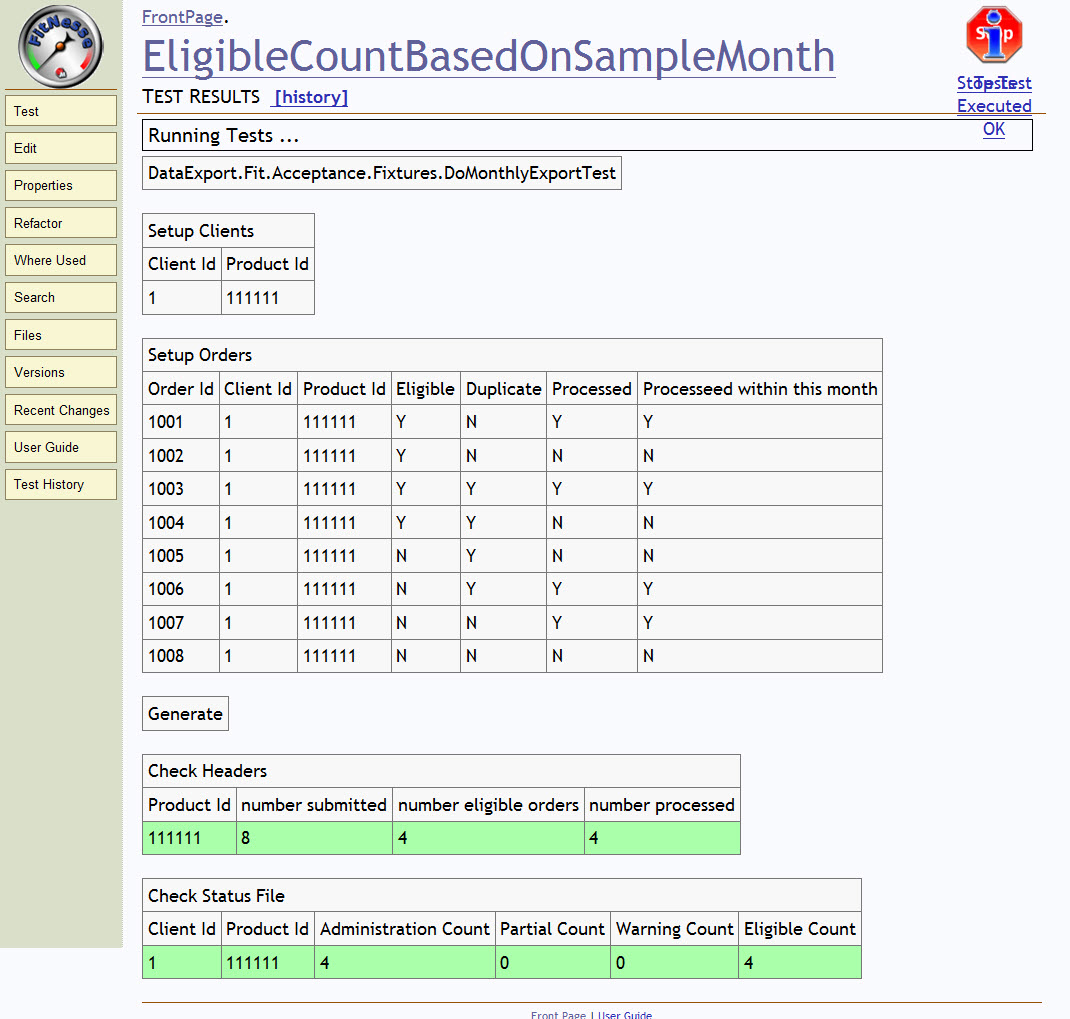
Figure 1
What I see is that it creates eight orders, only four of which are current. It properly displays eight submitted and four eligible.
But, wait a minute. Notice that every column has four Ys of some type. Our summary shows four eligible orders. Our summary also shows four processed orders. Which four eligible orders go with which processed orders? Which Ys in the test correspond with "eligible" and "processed"? We don't know.
To test this check, I click the edit button, change the N eligible for order 1007 to a Y, and rerun the test. Everything still passes. The number of eligible orders in the header and the eligible count in the status file are both still four. I expected them to increase to five.
What's going on here?
The Requirements
Notice the name of the test, "EligibleCountBasedOnSampleMonth," and that the number of orders in the sample month is still four. My naive reading of the check led me to ask, "What if some columns are different?" and that led me to change the check. I did a test, and now we have a more powerful check. We're now better at demonstrating where eligibility comes from, and the check is more likely to catch regression errors. For that matter, I can change all the columns to have a different number of Y options and explore the results.
And that's kind of the point.
Running these checks over and over without thinking about them has some value; they are effective change detectors. When I click the edit button, change the inputs and expected results, and run again, I am testing. I am thinking in the moment. The tool gives me the ability to ask "What if?"—to explore and to find out if a problem exists.
Two years ago, if I wanted to explore in this fashion, I would need either to set up an input file into the database with these values or to run a series of INSERT and UPDATE statements on the existing database, hope I got everything right, run an MS-DOS executable, and then view the resulting file.
Whew. That isn’t fun.
Of course, I'm going to run some tests by hand to make sure the checks are still relevant. Once I believe the checks really do tie out end-to-end, I can play "What if?" all day and get feedback in seconds rather than the ten to thirty minutes an old run took. That is power.
But, Is That All?
The type of testing I describe in my previous article is feature testing, and, if you keep them around, the tests do produce a regression suite. That has some limited value, but regression testing the same values is sort of like walking the same steps through a minefield, checking to see if anyone has planted a new mine in exactly the same spot you walked before. You'll miss anything else that could be defective in the software under test. When we consider the additional time to institutionalize the test—to write the hooks in the code, to create the fixture—it turns out to be a very expensive walk through a cleared minefield.
Please, don't get me wrong. This kind of checking can be helpful, but it is not sufficient. The teams I work with also do exploratory testing around the newly developed features, compare test runs against random data from the previous build, and do performance and unit tests. Most of the successful teams I work with take a "balanced breakfast" approach.
Takeaways, No Matter the Method
Today we are talking about specification by example, ideally examples that a business person can understand. These examples can come from the whole team, with the programmers writing the automation. This leaves the testers with a collection of power functions they can change as simply as clicking Copy > Edit. Sometimes, testers can use these functions to reproduce bugs found in the field. I have even seen cases where the testers did the reproduction in the tool, then handed the failing case to the programming staff saying, "Here's the bug. The story is: Make this failing check pass without introducing any regression error."
It takes a lot of work to get here. All that time spent writing automation could be spent on new features, and the testers could be doing exploratory testing that has immediate value. Some checks become green and are forgotten, or future changes introduce different behaviors that are perfectly correct, yet cause tests to fail. All of these things are tradeoffs.
This morning, I reviewed the tests, pruning the old ones, asking "What if?" and adding comments and links in our online story-tracking system right within the check. All of that was based on many hours of work creating the automation system. Nothing is free, but would I go back to that old world where everything was by hand?
Let's just say that it is hard to imagine.
That's my story. Where are you on the continuum? What is your team doing?

1 comments
I think the argument for automated tests such as Fitnesse as 'change detectors' and 'regression alerts' is strong. What I'm unclear is at what level Fitnesse tests like this one interact with an application. Are they at an API level? Are they GUI level? Do they hit Web Services? Maybe this is a question whose answer will vary with the context?
While I've not yet had a chance to look at Acceptance Test Frameworks like Fitnesse, I'd be interested in learning more. For example, for a project manager who sees the need for something, why should he choose Fitnesse? What benefits does it hold over using internal Unit Testing? I for one would love to hear more. I often see room for more 'testing' to improve the process, but it isn't always clear what 'testing' is needed in any given context, or whether a tool like Fitnesse would be a help, or just another group of documentation/code to maintain.

")

Lets Hang!