Summary
Joe Farah gives a primer on a next generation ALM tool that reinforces the concepts of next generation ALM. Next generation ALM tools are, well, somewhat futuristic. After all we're talking about the next generation. But it's hard to talk about abstract and idealistic concepts if they are too hard to picture.A Primer on a Next Generation Application Lifecycle Management Tool
articleBy
|
Next generation ALM tools are, well, somewhat futuristic. After all we're talking about the next generation. But it's hard to talk about abstract and idealistic concepts if they are too hard to picture. There are a number of tools out there that demonstrate clear 3G and 4G properties. And new ALM Tools are emerging on several fronts. Having written this column since mid-2004, I decided this would be a good time to show a bit more of the leading edge; a next generation ALM tool that reinforces the concepts of next generation ALM. I think it may affect the way you think about ALM tools. It will also, hopefully, affect the way vendors think about their own tools, and especially about the future.
CM Generations
If you've followed my columns over the years, you may have a good idea of what makes up a 1G, 2G, 3G and 4G tool. But let's try to put the definitions succinctly.
1G CM - Let's you reproduce your builds.
2G CM - 1G, and allows you to track changes (as opposed to file deltas) conceptually and track why each change was made. It also provides a relatively easy to use interface, usually graphical.
3G CM - 2G, but with a strong focus on ease-of-use, role-based custom process, and low cost of operation. It integrates the entire product team, possibly geographically distributed, rather than just the development team, with a common architecture across all ALM functions. Forms and reporting are unified into data navigation and object-oriented actions.
4G CM - 3G, but the way you want it, with little effort to get it that way, across all ALM functions, and even beyond ALM when necessary. Throw away the tool training manual - focus on your process. Automatic data capture occurs from the environment, context and actions, where possible, to ensure data quality and completeness, while simplifying the end-user task. Focus moves from navigation and actions to roles, meetings and tasks, with custom dashboard stations to manage each.
OK... I'm starting to get a bit wordy here. And the last time I wrote about CM Generations, I think it was my longest article.
So how do we rate today's CM/ALM tools on the CM Generation scale? Well, it's not getting any easier to do. Subversion, for example, is a 1G tool, with a number of post 1G capabilities. But add on the layered and complementary products and it becomes part of a more advanced ALM tool. RTC has some great 3G capabilities, and assuming it's sufficiently scalable, is very forward looking in nature, but it's architecture weighs it down as a hybrid 2G/3G tool overall. MKS has some great technology too, but again weighed down by its "big-IT" architecture and its less mature CM function versus its very strong process architecture. Neuma has some really nice technology in its CM+ product - and we'll use it in this article to help demonstrate some of the Next Generation ALM tool concepts.
Next Generation ALM
When we talk about Next Generation ALM tools, we're focusing on late 3G and early 4G architectures. So what are the big areas that make a tool NG. A quick summary:
- Ease-of-use by role and task - not just by tool function. Translation: miminal tool training.
- Seamlessly Integrated ALM functions. Not just functions that work together with traceability. Common architecture.
- Zero-administration, or at least darn near. You don't need to hire someone for CM/ALM administration.
- Low TCO (Total Cost of Ownership). Across the entire ALM function.
- Extensive, and very easy customization. The way you want it, with little effort.
- Secure, global operation, surviving and auto-recovering from network outages.
- Ultra-high reliability. Fail-safe. Disaster recovery capabilities. Data sabotage recovery. Always available data.
- High performance and admin-free scalability, both upward and downward.
- Process orientation, with minimal scripts. Process is structured to support automation and guidance.
- Context-aware. Data is populated based on your environment, actions, and structured strategies.
- High-level navigation, data mining and interpretation, with minimal effort. Custom focus on info access by role.
- Invisible complexity. CM/ALM is very complex and needs to be more so. But it must hide this complexity.
- Platform architecture. Not limited by the latest hardware/OS platform. Can co-exist across multiple platforms.
- Mature, advanced, out-of-the-box process. Support across development disciplines.
- Strong data architecture - supporting all engineering and management data efficiently and effortlessly.
3G ALM is all about ease of use and low costs. Ease of use needs to be considered for all roles including Administration, CM Manager, and the various vertical users (Testers, Developers, Managers, Project Managers, etc.). Low costs need to be considered across all aspects of the ALM function and environment. This includes user productivity (all roles), down-time avoidance, ALM tool evaluation/deployment, ongoing administration, cost of customization, cost of solution upgrades, license costs, annual maintenance, process support, integration costs (3rd party tools or between ALM point tools). And both ease of use and costing need to be considered across all ALM functions. 4G ALM takes ease-of-use to a new level, and excels in ease of customization.
If you can hit these, you're well on your way to a Next Generation ALM solution. At the risk of being subjective, we'll look into the future by looking at a tool that stacks up well against these criteria.
An Overview of CM+
CM+ is an ALM tool that started out, circa 1990, as an ALM tool. It did not grow out of a version control or even configuration management tool. Hence the "+". CM+ sits on top of what is known as the "STS Engine". This engine combines a next generation "hybrid" database/repository (relational, object-oriented, revisioned, large object, tree-/network-oriented data), with a process engine (rules, triggers, permissions, access, encryption, state-flow, guidance), and a customizable user interface capability - the GUI Generation Engine. The UI can be fully command-line oriented (CLI), fully graphical (GUI), or a mix. The STS Engine was designed to support the number one goal of CM+, to support the process the way the corporation needs it. It was also designed to be ultra-reliable, extremely scalable, and administration-free.
CM+ is an application layer integrated on top of the STS Engine. It's strength derives from the strong CM background of its founder at Nortel and elsewhere. The out-of-the-box CM process is mature. Change packages, known as Updates, were built in from the beginning, as a central component to change. Although branches are lightweight in CM+, Neuma encourages minimal branching (i.e. for parallel release management) by providing other mechanisms for tagging Build and Baseline definitions, promotion levels, and short term parallel checkout.
Perhaps the strongest element of CM+ is the ability to easily customize all aspects of the ALM tool. The focus here is on "easily". For example, a trained CM+ consultant can create an extensive dashboard in a few minutes. Virtually everything can be customized: state-flow, commands, dialog panels, dashboards, pull-down and pop-up menus, tool bars, quick links, active reports, guidance, help, data schema, application function set, color scheme, etc. The nice thing is that there's hardly any scripting - it's primarily data driven or a single line command per customization. Once familiar with the basic architecture, you stop asking "Can it..." and you start asking "How".
But the first thing that a user tends to notice is the level of traceability and seamless integration of ALM functions. Have some data and need to see where it comes from or what it leads to - just a click away - and if it's not, make it so. It is extremely responsive, so that you may traverse several links in just a few seconds, individually or collectively. The information is at your fingertips, in a variety of formats.
CM+ supports the common ALM functions: Version Control, Change Management, Customer Requests, Requirements, Problem Reports/Defects, Projects/Activities/Tasks, Configuration Management, Build and Release Management, Test Case and Test Run Management, and a few other areas, all built on the STS Engine. So traceability is pervasive, as is the commonality of User Interface, Administration, Customization, and Multiple Site management across all ALM functions.
Much of the power of CM+ comes through its command and data query language. Virtually any set of repository items can be easily computed through a data expression. For example, you may subtract the revision history of one file branch from the history of another to see the changes made since their common point. But you can just as easily do that for the entire product tree or any subset thereof. You can use boolean logic, intermediate variables, special operators (hist, expand, members, etc.) or "field" operators (e.g. <expression> title "crash"). These data expressions can be used in most of the CM+ commands, reducing, what normally is a programming task, to a relatively simple data expression.
The end-to-end definition itself is easily customized. You can add in Project Portfolio Management, Time Sheets, Customer Tracking, Lab Management, or any number of functions which can be developed and deployed in a few hours to a few days each.
CM+ set is rapid (i.e. a few minutes) and data loading is quick - both files (multiple baselines) and other data (problem reports, activities/tasks, and requirements). Export of data is also flexible and fast. So if you really don't like CM+, it's a good starting point for moving to another tool. CM+MultiSite is easy to deploy, nearly administration free, and you can add sites as you go, without taking down the system. Upgrades take minutes, with a couple hours preparation if you have significant customization.
CM Capabilities
One of the first things to look at with any ALM tool is its level of CM capability.
1. Change Packages
Even a 2G CM tool must define change packages, and a 3G CM tool must fully integrate these into the process and behavior of the tool.
CM+ Updates were designed in from the beginning. You don't promote files, you promote Updates. You propagate (i.e. merge) an Update. Equally well, you can "yank" an Update. Dependencies are expressed between Updates. Even before the creation of CM+ in 1990, Neuma's founder had already enjoyed over a decade of designing and deploying systems where the change package was central to the CM function.
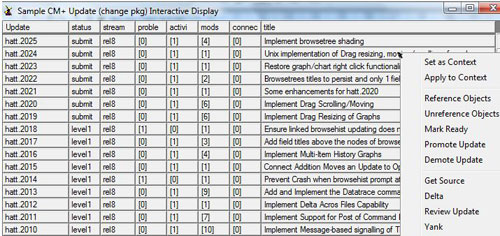
Fig. 1 - Interactive data display panel of Updates. Click on the Update Id, a "[N]" field, or a title field to zoom in. "mods" field will show the list of files associated with the Update, from which you can further zoom in. Similarly for "problems", "activities" and "connections". Display panels are available for all types of data records.
Updates are numbered sequentially for each user, making them easy to identify. There are typically several traceability links as part of an update - usually automatically filled based on object-oriented user actions used to create each Update. Peer reviews are always performed on complete Updates (as opposed to individual files).
2. Branching and Labelling (Tagging)
Branching in a next generation tool must support our process. But the branching strategy has to be one that is understood by the tool. In a next generation system, the tool must be able to help support the branching, and should give clear guidance to the user of the need to branch, eliminating, as much as possible, the reliance on their own interpretation of branching strategy.
Although branches in CM+ are lightweight, and labelling capabilities (and query thereof) extensive and efficient, various tool capabilities minimize the need for branching, labelling and merging. Most CM+ customers use a branch-per-release configuration, with, perhaps, additional branches for long-term changes. CM+ does not require branches for promotion, short-term parallel checkouts, tagging, or other organizational issues.
A Trunk per Release structure, instead of a Main Trunk, simplifies the end-user view of the world, and the logistics of opening and supporting a release development stream. As a result, branching, and merging, are much less frequent.
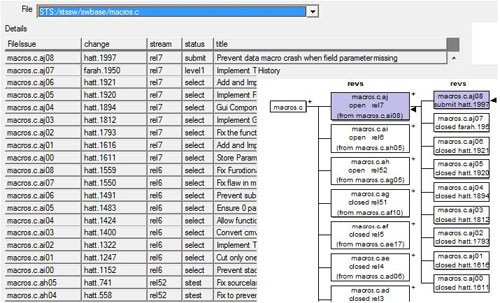
Fig 2. A typical history browser shows the Update status and title for each revision (display panel), but also shows the branch history (click branch to see its revisions). Shading shows current context, arrows show workspace content.
Trunk per release branching is done across the entire product source tree hierarchy (files and directories). Each release trunk is referred to as a development stream, or simply "stream". The branching history of a product root indicates the history of development, and this is used for calculating the appropriate revision of a file to use when it hasn't been modified for a few releases or for computing merge ancestors. CM+ will tell developers if they are required to branch, rather requiring them to learn a branching strategy.
Overall, the capabilities of CM+ allow you to use branching for parallel development, rather than overloading the use of branches. This in turn has dramatic impact on learning curve and on automation.
3. Context Views
Users tend to work in specific contexts, and so they set a view to the CM repository that reflects that context. Most common views reflect an existing release or build for a given product, or the latest revision of a development stream, perhaps at a given promotion level (e.g. the latest integration tested revision). The former (release, build) are static, while the latter are dynamic. Next generation CM tools must not put the user at the mercy of specifying revision numbers. The context needs to do this. I specify the context I want to work with, and from there on, I don't have to worry about file revisions.
In CM+, context views can be static or dynamic, or a mixture. You can customize a context by adding in Updates or specific file/directory revisions, though this is seldom necessary. CM+ remembers the workspaces you've used with each context allowing you to select one whenever you switch context. The default source tree does not show revision numbering, but a click on any item will give the information in the data panel. When viewing a static source tree, CM+ allows you to see specific revisions, and even highlight those that are different from another context.
Contexts views in CM+ don't just apply to the source and requirement trees. They apply to everything you do - query presentation, field defaults on a form or dashboard, pick-list selections, and various others. The result is fewer key-clicks, more intelligent and easy-to-use user interfaces, and ultimately better data quality. Some dashboards let you select a context specific to that dashboard, such as a product manager might want when looking at each release.
4. Developer Features
An ALM tool must reduce reluctance to usage. In a large team, it might be easier to convince someone that they have to learn all about the CM/ALM tool. But it had better do the job. And in a smaller shop, well, they might need more convincing. Reluctance may be a result of "overhead" or it might be based on past experience. In a next generation tool, there are many benefits to the user, regardless of role, that leave them not wanting to do anything without the tool at their side.
Reluctance is quickly overcome in CM+ through numerous capabilties available to the developer. These include:
- Source-code search across any file or sub-tree, or across all (or a subset of) revisions of a file or sub-tree.
- Rapid identification of prioritized items/in-progress work on the developer's to-do list (typically in the quick-links).
- Object-oriented and context sensitive operations reduce keystrokes/clicks, while increasing traceability.
- Rapid comparison of any context to a developer workspace. Easy workspace deployment & "rebase" operations.
- Active workspace indicators in the source tree: files missing, checked out, changed, older/newer revision, R/O, etc.
- Easy search through File History, Updates, Problems, Activities, etc. Easy identification of work accomplished.
- Rapid identification of differences between builds - from source code deltas to update/feature/problem descriptions.
- Update-at-a-time operations: check-in, promotion, delta review, change propagation/yank, etc.
- Rapid source-tree navigation (much quicker than typical file system), and context switching (e.g. between releases)
- Automated Update generation based on changes made to workspace.
- Bulk loading of new code directory trees in a single operation.
- Automatic updating of progress information for traceability items.
- Consolidated dashboard views to present information without the need to ask for it.
- Integrated guidance - customized to project. And small learning curve.
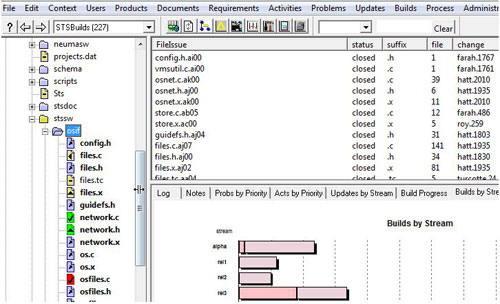
Fig. 3 - A snippet of the main CM+ panel shows the active workspace. "osfiles.c" (red) is checked out by another user. "network.c/.h" (green) by the current user. Workspace content of "files.c files.x & network.h" differ (delta symbol) from the context view. For "files.c", the workspace copy matches an earlier revision. "files,tc" is missing. R/W files shown in bold. Quicklinks are found below the source tree, or in the pick-list above it. Most icons in the toolbar are for dashboard access.
To gain buy-in, you could start by interactively taking developers aside and asking them what they'd like to see in their personalized developer dashboard(s), and then showing them their dashboard that same day for feedback. This doesn't just apply to the developer role though. Users of every role on the product team need to buy in to the ALM solution: QA, technical writers, developers, CM managers, testers, product and project managers, etc.
5. File Dependencies
CM+ may be the only CM tool that allows you to track include (or other such) file dependencies on a per context basis. With every check-in operation, CM+ can be configured to scan and record the include relationships within the database. This is typically done for specific file classes (C, C++, etc.). You may then ask CM+ about the relationships:
- What files does this file include?
- What files depend on this file?
- What files are affected by this update?
- What needs to be recompiled as a result of the updates that were selected into today's build?
- Are there any circular include paths?
You may establish any context and do these queries - no need to consult source code - and the response is pretty much instantaneous, even with tens of thousands of files.
This dependency information allows generation (and launch) of Makefiles and other build files. Wouldn't you like to stop maintaining your Makefiles? One Makefile is generated per target. You can ask CM+ to generate (and then launch) an entire set of Makefiles to build all the targets. This can be combined with Include and Object search directories to support incremental build processes, or to eliminate the need to build intermediate "archive" libraries for static builds.
But there are restrictions. For example, conditional compilation instructions around include statements will be ignored, resulting in apparently more stringent dependencies. [CM+ doesn't know what the conditions will be at compile time.]
6. Directory Revisions
CM+ manages directory revisions without the need for developer checkout. Developers, as part of an Update, may remove files, add files, move files around in the tree, through a tree operation: click the directory or file you want to remove, or to which you want to add a file/component, and select the appropriate operation. Or drag and drop files and directories within the tree. CM+ prompts to associate the operation with the correct user Update. Then those operations move around with that Update. Add such an update to your context (or use one that includes it) and you'll see the structural changes; remove it and they'll be gone.
7. Configurations, Baselines and Builds
Each combination of product, stream, and promotion level defines a (dynamic) configuration of the product for a stream. As Updates are promoted, these configurations change (i.e. they are rule based). An align operation, typically performed by the CM manager, allows the rule-based configuration to be transformed into a static list of file/directory revisions. As necessary, if the latest directory revision is frozen, a new directory revision is created to reflect changes within each directory. At some point an aligned configuration is frozen (i.e. it becomes a Baseline). The configuration may be aligned multiple times (e.g. after some last minute features) before it is frozen. The Baseline is simply the revision of the top-level item that was frozen. All future changes will go into a later revision of the configuration. There is no need for developers to checkout or configure a directory.

Fig. 4 - Hierarchical Baseline definition, comparing a new release (changes shaded) with an older release.
Manage the superset, build the subset. If you have a number of variant builds for each release, don't create a baseline for each that has to be individually managed. Instead, create a baseline for the superset of all files for the release, and create build records in terms of that baseline. This is the recommended CM+ operation. A Baseline is a hierarchical decomposition of specific revisions of each directory component within the product tree - a frozen configuration.
A Build definition takes a Baseline, or a subset (e.g. a sub-tree), possibly adds some variant information (e.g. English, Enterprise Edition), and then adds Updates to be applied on top of the baseline (e.g. a couple of bug fixes done after the Baseline was frozen). This fully defines a set of revisions but in a very different manner - one that is a lot easier to compare and understand than two sets of file revision enumerations.
In CM+, baselines are identified by the revision of the top-level directory (i.e. the product root node) of the baseline, and builds are specified by a (possibly auto-generated) name. Typically, a series of Builds proceed from a Baseline as Updates are checked in and new builds required (e.g. nightly builds). Most larger shops will automate this process by kicking off a Build definition process, and subsequent build operation. The build definition process, whether automated or manual, consists of the following steps:
- Select a Product and development Stream context to work in.
- Promote any Updates targeted for the Build (e.g. Update status moved from "ready" to "selected" for hot fixes)
- Start the new Build definition based on either the previous Build, or on a Baseline.
- Add the promoted Updates to the Build definition.
- Perform a trial build and quick sanity test. If successful freeze the Build definition. Otherwise fix issues and go to 2.
Just like a Baseline definition, a Build definition may be used to populate a workspace, establish a context view, or establish a Baseline. Unlike a Baseline which is a Configuration that is Frozen or not (i.e. not yet a baseline), a Build has a full range of Promotion Levels through which it will pass.
8. Update Promotion Dependencies
Update promotion can cause dependency problems. Suppose "black.123" depends on "jones.321" and "jones.321" is not yet ready. Promoting black.123 would raise a dependency exception that would have to be addressed - either eliminate the dependency, roll-back black.123 or ensure jones.321 is also promoted. A dependency may be expressed explicitly (e.g. black.123 depends on jones.321), or implicitly (e.g. black.123 changes timer.c which was earlier changed by jones.321). Similarly, rolling back (i.e. un-promoting) an Update can cause dependency issues.
Some shops eliminate dependencies by stating that a changes cannot be checked in unless they (and all of their dependencies) are ready for the build. This delays checkin and creates the need for more parallel change and merging. CM+ detects both implicit and explicit dependencies and identifies them (in the default process) first to the developer (when (s)he says the Update is "ready"), and then to the CM Manager (when the Update is promoted for the Build operation).
Other ALM Functions
A next generation system must handle the full range of ALM functions. It is not sufficient to treat documentation and test cases as simply more source code. For example, some documentation is much like source code, in that it follows the same release evolution, and requires the same checkout/checkin and traceability through a change package.
But other documentation is quite different. Quality reports, technical notes, customer documents, etc. all have different sets of requirements. They don't typically follow a parallel stream "development" path. Often it is preferred to have their identifiers allocated automatically (e.g. TN.115 for a tech note), and grouped together, rather than to have someone devise a name. Sometimes their sequential in nature, like the PRB meeting reports. Sometimes they need multiple revisions (e.g. customer document reissued), sometimes they only need one (e.g. 2012 Federal Budget).
Test cases are often better off as non-revisioned short tests (e.g. commands to be entered), with changes to a test case appearing as a new test case (i.e. tc.2143 replaces tc.1399), rather than imposing a version control mechanism on them. In other cases, where a test case is often of significant substance, it might be better to have some version control as well. In any case, there does need to be version control of the test case configuration. Typically a tree structure is needed to group test cases into test modules and suites.
Requirements have text, and perhaps attachments. They may use "note" fields (i.e. database large objects) for the text, rather than storing each requirement in a separate file. Requirements definitely need version and change control. They are typically arranged in a tree structure. Often one of the most useful capabilities is to be able to compare baselines of requirements.
Tasks and problem reports (aka. defects, bugs) tend to be more data-like in nature, although tasks are often grouped into WBS (Work Breakdown Structure), for organization and for roll-up purposes.
With all of these different requirements for management data across the ALM, some tool suites pull together the best of breed and then provide integration glue. But then there's the management of the glue, the dealing with new releases of each functional point tool, the array of administration, global access, user interface, etc. processes specific to each tool.
CM+ addresses these functions by providing a flexible base through its STS Engine. You can create a function by starting with a data record description, adding whatever type of fields are necessary into the record. These can include, for example, sub-tables (e.g. a document has a set of document-branches, and each document-branch has a set of document-revisions), notes, attachments (i.e. files), title, reference lists (including to the same table, forming a tree), etc. CM+ provides a default layout for the data, and the rest of the application definition (state-transition flow, object-oriented pop-up menus, pull-down menu, dashboards, etc.). In some cases, it provides more than one application definition to choose from.
But you can take any starting point and very easily customize it to the requirements. The STS Engine supplies the bulk of the capabilities needed for the application. And as a result, it can take advantage of the same backup procedure, disaster recovery, multiple site operation, process definition language, schema definition language, GUI customization capability, etc. as used by the other ALM applications. Traceability, reporting, forms, browsers, and other common aspects all come for free. Customization becomes a specification process:
- What data fields are needed, and what properties do they have (e.g. owner, status, etc.)
- What reference fields are needed - this defines traceability, history and tree structures.
- What states does a data record go through.
- What are the state transitions, including rules, triggers, permissions, etc.
- What items are in the pull-down menu (usually starting from a recommended list)
- What items are in the pop-up menu (from a recommended list, plus others dependent upon state flow)
- What dashboards are needed for each role involved in the application
- What quick-reference information should be on the main panel (quick links, report tabs, process guidance)
In each case, CM+ allows you to manually specify each item in a single command line (add a field, define a state transition, define a menu item, define a quick link, specify a dashboard, specify a report tab, add a set of process guidance slides).
Because each item can be specified in a single line, it's fairly easy for CM+ (or for the customer) to create menu items to do these things graphically. And the CM+ Process menu is usually the place that this is found. A bit later, when we talk more about customization, we'll look at a couple of examples to make this clear.
Platform Architecture
Platform architecture of a tool speaks, not just of which platforms it can support, and which can inter-operate successfully, but also of how quickly the ALM tool can be ported to a new platform. After all, in 10 years, when your project is still going strong, will Windows still be the dominant client, or Linux the dominant server architecture? Hard to know.
CM+ was initially designed as a CLI-only tool, because Windows 3 and X-Windows were in their early evolution when CM+ was being designed. The goal was, though, to support the CLI (client and server), on any platform with the ability to port from one platform to another in a day or less. [Until the appearance of the GUI, this worked well.]
This meant that the STS Engine had to be independent of big-endian/little-endian issues, and eventually 32-bit/64-bit issues. This was designed into the engine - stop a server, move the files to a different platform, restart the server and it had to continue working without any user conversion. The (smart) client had to work regardless of what architecture the server was on. When multiple site operation came about in the mid-90s, it had to support multiple servers on different architectures working with the same repository, and clients connected from any architecture to any server. The focus remained on Unix/Linux and Windows platforms, as well as OpenVMS (which posed its own set of issues).
When the GUI came along, there was X/Motif and Windows (MFC). Only then, did GUI technology really start to take off. CM+ then decided to converge it's GUI technology, using WxWidgets on Unix, very similar to MFC. Still for other platforms, Neuma allowed for a Web-based client. And for the most part, customization of the Web-based GUI and the native-based GUI were to be one and the same, or at least have that option. In reality, Web-based GUIs tend to be much more focused than native GUIs, but that's all changing with HTML5. So the new challenge is GUI device format (e.g. smartphone vs laptop). This latter challenge is still being addressed.
To support data on all architectures, the STS Engine made sure that text files it read, such as scripts, could use any line ending mechanism, independent of the platform on which it resided or on which it was executed. It also made sure that the line-end encoding was not part of the version manager (called the Source Manager, or SM). So you can move files around without any issue with respect to line-end, and can retrieve files with whichever line-end convention makes sense.
CM+ has not yet fully addressed the MAC platform, although it did address both the NeXT computer (from which OS X comes) and MAC's AUX OS (MAC's first Unix).
Dashboards and Work Stations
Dashboard technology started out as a way to monitor project status from a high level. The ability to zoom into details was quickly added. Next came the ability to use the dashboard to do work - at this point I like to refer to this type of dashboard as a "Work Station". On the heels of this was the ability to customize the dashboard. This started out as a development tool for the tool developers, but now the push is on to let the customer customize.
A next generation ALM tool must let the customer customize dashboards. The customer knows, for each role, what is needed. And although CM and many ALM functions are well understood, they are far from any sort of standardization. CM and ALM are among the most diverse functions, with a common goal, that I've seen. And it will stay that way as new development methodologies continue to evolve.
Back to the main design goal of CM+... the way you want it. So it was no different with dashboards. CM+ already had in its architecture a GUI generation capability that allowed you to put data, notes pick-lists and other form-like data on a panel so that arbitrary prompt dialogs could be easily generated. Neuma extended this technology for its late 3G releases, and then more for its 4G releases. It`s now easy to specify a custom dashboard through a single command, though this is usually broken up onto multiple lines.
So, to give an idea of what I mean by "easily" customized, consider a dashboard such as the Problem Dashboard defined by:
dashboard ?/products/[@cur product]Product
?,{@data 'revs rootnode ?Product' stream}[@cur stream]Stream
?,<Date>10x32[9/10/01]Since_Date
?/probs product ?Product status < fixed/(stream priority)#Problems_By_Stream
?,/probs product ?Product stream ?Stream/100(priority status)||Priority_By_Status
?(probs)[status]Sort_By
?,(probs)[priority]And_By
?,/probs product ?Product stream ?Stream status < answer/(:8 status priority assignee title:40)Open
?/probs product ?Product stream ?Stream sort ?And_By sort ?Sort_By/7(:8 status priority assignee title)##Problems
?,<>8x100[>get -term ?Open -field notes]Notes
?/probs product ?Product dates.orig > ?Since_Date/80(dates.orig:32)|Arrival
?,/probs product ?Product dates.fixed > ?Since_Date/80(dates.fixed:32)|Fixed
?'Problem Dashboard'
Each line above corresponds to one of the widgets on the dashboard. Each prompt starts with a ? and ends with a name. In some cases earlier names are referenced (?Name) to make the widget dependent on a previous one. But overall, this specification is very straightforward, at least when you understand the basic widget specification. I'm certain any techie out there can readily relate the definition to the dashboard elements.
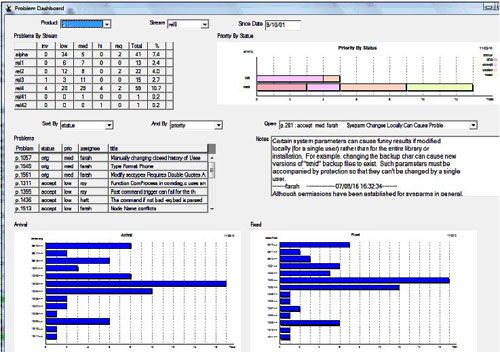
Fig. 5 - The problem dashboard is defined through a "dashboard" command that allows you, using a very high level language, to put what you want to see on the dashboard, and to allow you to dynamically select the data you're interested in viewing (e.g. Product/Stream/Start Date). The STS Engine automatically provides capabilities such as graphics zoom, interactive charts (click on a bar to show a data display panel for it), object-oriented pop-up menus, and drill-down tables and data display panels.
In this dashboard, the user can select any product and then any development stream, and look at the details such as "priority vs status" for the stream, or look at a specific problem, or perhaps zoom into the problems fixed in a particular month for specific details (i.e. by clicking on a graph bar).
As you can see, the issue isn't generating the dashboard, it's specifying what you want on the dashboard. And if you have enough widget variety, you're all set.
A developer might prefer to see an Update Review dashboard, from which he can select the update and file (within the update) he wants to view, add context around the delta report, or add review comment. The dashboard is defined by:
dashboard ?/changes @user status <= ready or reverse updates/(status title)[]Update
?/mods ?Update/(..title)[]File
?,4[@setcount 'mods ?Update']File_Count
?,4[1]Context
?,4[3]Match
?<>25x160![> delta ?File -match ?Match -context ?Context oldnew -dir ?^deltaworkarea ?Update]Delta
?<>4x120[?Update-Review.txt]Review
?<>4x120[>get -term ?Update -field notes]Notes
?/problems ?Update/2(status title)##Problems
?,/activities ?Update/2(status title)##Activities
?'Update Review Station'
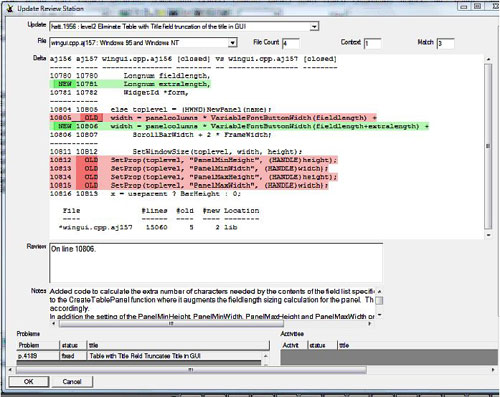
Fig. 6 - A simple Update Review station. This configuration shows a single file at a time. It may trivially be converted to show all of the file deltas for the Update at once, in the scrollable window. A review can be added directly from the review station. You may zoom in to the traceability elements (in this case a problem report) while reviewing.
Notice how each of the components of the Update Review Station dashboard has a corresponding, but simple, line in the definition, just as for the Problem Dashboard. The definition lines may be "coded" manually, or generated through a dashboard specification station. But in any case, it's not difficult to see how to specify the dashboard elements. The fact that some elements are defined by selections earlier in the dashboard are what give the dashboard a dynamic context.
So, for CM you might ask the vendor, "what dashboards does it have?". But in CM+ you'll ask the user, "what dashboard(s) do you need for your roles and tasks". And that's what you want - dependence on the user, not on the vendor. And if they don't quite like it, add a line or two or modify the presentation to suit the user's needs. Hey, this sounds like Agile development. And that's just what it is, but for your CM Tool, after you've acquired it.
More on Customization
Customization is a critical part of next generation ALM. But if customization costs a lot, it won't get done. Or if, once done, it's too hard to change, it can't be widely used and will grow stale. That's why customization has to be easy to do (have I said that already?).
The dashboards of CM+ appear easy to define. The first customization goal for any next generation ALM tool must be to take the definition capability away from the compiler, and away from the developer, and even away from the consultant, and give it to the user. In reality, the customer often can't be bothered customizing, so it may be better to leave it with the consultant.
The next customization goal for next generation ALM tool is that customization must be incremental. Don't make the customer specify it up front because he generally doesn't understand the process fully at the end of the product lifecycle, much less at the start.
The next customization goal - it must be extensive. Give me a database and a process tool and I can have all the data I need for the ideal process. But if I have a lousy user interface, I'm in trouble. Every aspect of the user interface needs to be customized (OK, perhaps you don't need the standard "themes" package). The tool must speak the language of the corporation. It must understand the branching strategy of the project. It must ask for only the information required, and pick up the information from the environment otherwise. It must allow you to put buttons and menu items in place without hassle. Quick links too.
CM+ gives some great examples here. Some customization lines from a the quick links definitions:
browser MyProblems
reverse (probs @pcontext assignee @user status < answer sort stream)
(:12 status date:10 priority:6 product:9 stream title type originator:12 )
-leaf -refresh -expand 0 -title -fields -trim
browser {designer cmmgr super} MyUpdates
changes @user @pcontext status <= ready class not requirement sort status sort product
(:18 status product:10 stream title problems activities)
-leaf -refresh -expand 0 -title -fields -trim
These define two quick links in the browser panel: Optionally roles that include them - quick link name. Then a data expression identifying what the link corresponds to. Then an optional list of fields and default sizing. Then some options. Now it's very easy to put this in a dialog panel.
comment ?{@roles}*Roles ?16[My]LinkName ?DataExpression ?<Table>Table ?(?Table)*Fields ?{-leaf -refresh "-expand 0" -title -fields -trim}*Options ?"Define Quick Link"
And this defines the panel:
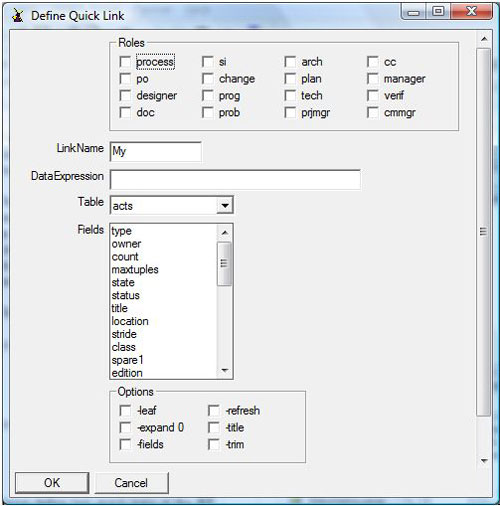
Fig. 7 - A sample Quick Link Definition panel defined in a single line of code.
That took me less than 5 minutes to define. That's why it's easy, not just to customize CM+, but to simplify customization. Clicking OK will type out the line to put into my "browsers.gui" file - and my quick link is defiined. OK - but what about that data expression - more on that in a bit.
Menus are equally easy to define in CM+. For example:
@popup "Assign Problem" change "@user prot not with prjmgr" "assign @1 assignee"
@popup {prjmgr cmmgr} "Assign Priority" change "" "change @1 -field priority"
This defines two of the popup menu items for a Problem object. Optional roles, button name, category, qualifier, command. Again very simple (@1 is the unique id of the problem object). Some menu items are more complex, but usually range from one to two lines. Again, very easy to define a menu item definition capability. But an expert is often happier to use the command language.
Ah yes, there's another gotcha. Command language, data expression, GUI generation language, macro language. We've seen that the GUI generation language is very high level. So is the data expression language. And the macro language is quite capable. There are over 100 commands - some configure options, some bring up displays, graphs and tables. Some do basic CM operations. Others do basic database operations.
In CM+ you can do a lot of customization without learning the "languages". But there's a lot more you can do if you learn them, and you can generally do it faster. So what CM+ does is to allow you to interactively use these languages so that you see instant results. Type in: note ?<Stream>Stream. You'll see a panel pop up with a stream selector. Add a ?/products/Product, and a Product selector appears as well. Put a comma after the second ? (called a prompt character) and it appears on the same line. This is definitely a fun way to learn. And you can gradually build up your repertoire. Now when you see a command, you specify a prompt in place of each parameter, and all of a sudden the command has a full GUI. Use macros to combine commands or to help you specify default values for your prompts. Then use the prompts which require data expressions: a graph, a table, a display panel, a reference list selection, etc.
The point is not to extoll the virtues of CM+. It's to point out that when you define languages that can work together, you get a lot more than the sum of the languages. A prompt can query the current stream context and use it as a default value. In fact, it will automatically do this for you unless you override. It will also remember what you previously selected and use that as a default. The data expression language can be used with the macro language to extract data from the repository to use as a default. Or a data expression can be used to specify what you want in a pick list. This ramps up the power of customization dramatically. Add in the capability to save often used prompt snippets and you've got a great, concise dashboard specification language.
Customization capabilities must be a key part of a next generation ALM tool. And although nice GUI panels might be an easy way to perform common customizations, it will not take you nearly as far as you can go as by having a nice set of orthogonal language components that can interwork. Yes, GUI panels don't require a lot of training (so anyone can do the basic customizations in CM+, such as inserting a field, adding a state or transition, or even creating a menu item. But a simple and very high level language capability for defining/using macros, GUI prompts, and data expressions will give you full flexibility. Why not use Perl and TCL? Because they are not integrated. You have to do programming to get the integration. Take one of the dashboard examples above. How long do you think it would take to convert that to a Perl/TCL combination? A few minutes or a few hours to days? Now write a dozen dashboards. A day or a month? Now pass the scripting on to someone else to maintain. Which would they prefer?
Process
Process means a lot of things. In a next generation ALM tool, a process engine is needed that brings commonality across all ALM functions. MKS has done a decent job here for its ALM offering. But more than just a process engine is required. You need the ability to customize the entire tool to the process being used, whether it's a SEI's CMMI process, ICM's CM II process, Neuma's Unified Process, or your home grown process. Overall process look-and-feel, along with process terminology, must make its way into your ALM user interface.
Once the big picture has been settled, attention can shift to the smaller details. In large corporations, it's typical to develop an organizational wide process (consistent with CMMI levels 3 and higher), but to let individual projects customize this. The ability to specify roles, permissions, state flow, rules, triggers, and so forth, are an important part of customization.
CM+ supports state-transition flow for every class of item tracked in your repository, whether problem reports, updates, builds, testruns, documents or otherwise. It will even permit you to have custom flows (or partially custom flows) for different types within a class: Feature activities follow one flow, build activities another, and so forth. Each transition may be guarded by roles and permissions, as well as by rules and triggers. Basic triggers, such as email notification and logging of data changes, can be enabled through a simple checkbox selection.
CM+ also offers big picture configurations from which to start. The out-of-the-box configuration reflects Neuma's Unified Process. But switch to the CM II edition and you have something that looks quite different.
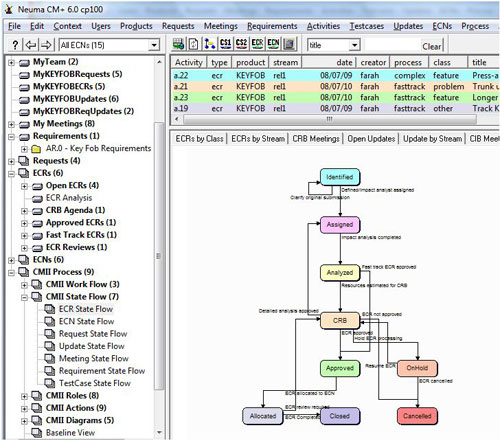
Fig. 8 - The main panel of the CM II edition of CM+ shows the ECR State Flow in color-coded fashion. The diagram can be edited directly in the CM+ panel. Note, in the top-right data panel how the "ecr" activities are color-coded to reflect their status. Similarly, gantt charts and summary graphs use the same color-coding to give a status-at-a-glance look and feel. Notice, on the left, the CM II process guidance, the requirements tree, and a number of "My" quick links. Custom CM II icons (near the top) allow you to zero in on the main dashboard used by each CMII role.
Roles and permissions are used not only for state flow, but for command access, user interface display, menu item inclusion, data access, and other such items. A number of predefined roles (CM Manager, Project Manager, Developer, Tester, Administrator, etc.) may be customized or new ones defined. Other CM+ process capabilities include access controls, electronic signatures, rules, triggers, data segregation, and customizable metrics.
Multiple Site Operation
CM and ALM tools try to address global access in different ways. Some partition the data across sites, with a common synchronization back to a main site every so often. Others have one writable site, with a number of mirrors for data access. Others simply provide the ALM tool in the Cloud (probably a local cloud rather than exporting their key software assets). Each of these have their advantages and disadvantages. In a next generation ALM tool, it is important to ensure that you always have a consistent view of the entire repository (that you can use for consistent backups). It's better if you don't have to do partitioning and synchronization operations, as these can be administration intensive. It's also important that a user can roam from one site to another without having to re-orient themselves for their current site.
CM+ allows global operation by allowing you to specify a number of sites (typically a few) which are to serve as server sites. Each site, in the default setup, has a complete copy of all data. Any transaction sent to one site is also sent to all of the other sites, with a master site responsible for establishing the sequence number for every transaction. This has the effect that each site looks and feels as if it is the one and only site - just like a centralized system works. Each site contains a full copy of the repository. So there is no cross-site data access issue, there is no consistency issue, and users can freely roam from site to site.
This has two very large administrative side effects. The first is that you have a warm stand-by disaster recovery capability. If a site disappears, switch to another and keep working. The same information is at each site. The second is that you are less reliant on backups because each site is a backup of the others. So you can do the backup when you need it rather than in case you need it.
Ah, but what if the problem is a deep hidden issue within the ALM tool - then you still need backups to fall back on. In theory, yes. However, CM+ keeps an executable log of everything that happens to the repository, with time stamps. This is known as its transaction journal session. So you really only need to make backups when you start a new journal session (as the number of transaction files can easily grow quite large over time). To make even these backups easier, CM+ allows you to move the entire repository to a "read-only" location. You resume server operation, and as it needs to, it will migrate changed data files to the "read-write" location. Given the 80/20 rule, you end up with a one-time backup of the Read-only state (which can also be used to establish new sites if you need them), and then you only have to backup a fraction of the repository (the migrated read/write files) for "full" backups.
CM+ allows you to specify sites that cannot receive certain files in a number of different ways (e.g. large video files don't go to sites with slow links). This is often done for security reasons in a contractor/sub-contractor model. Of course, in this case, that site is no longer useful as a repository backup.
Next Generation ALM
Who would ever have thought of eliminating backups? Or of letting the customer add their own ALM function add-ons into the tool? Well, those companies which are truly working toward next generation ALM tools have. Although we used CM+ as a sample next generation tool, many tools have 4G features - some for many years. The "virtual file system" of ClearCase should be considered a 4G feature (or at least 3G). RTC has some nice 3G/4G user interfaces. MKS has a solid process engine that lets the customer have ALM add-ons. And CM+ has many nice 3G/4G features.
The goal is to get there. If we define where we're going it's easier to get there. Even a dashboard is much easier to implement in CM+ once we know what's desired on the dashboard.
Next Generation ALM is not an Agile support tool - it supports Agile, Traditional and other methodologies. It has to handle the full range because the needs are different in each organization and project. But the ALM tool itself can be Agile, letting the customer incrementally, through trial and feedback, move the solution ever closer to the ideal. That's why I gave a lot of focus to Customization in this article. Will it help you to stretch your ALM solution requirements?
Topics:
configuration managementAbout The Author

Community Sponsor

")

Not specified
Lets Hang!