In a recent running of our performance testing workshop, the students said they really appreciated learning about "hockey sticks" and "onions," so we'd like to share these concepts with you.
The Infernal Onion
When we run a performance testing scenario, we usually start with a light load and measure response times as the load increases. You would expect that the response time would increase as the load increases, but you might not anticipate the dreaded "knee" in the performance curve. Figure 1 shows the hockey stick shape of the typical performance curve.
 |
| Figure 1: The classic hockey stick |
The knee is caused by non-linear effects related to resource exhaustion. For example, if you exhaust all physical memory, the operating system will start swapping memory to disk, which is much slower than physical memory. Sometimes a subsystem like a Java interpreter or application server might not be configured to use all available memory, so memory limitations can bite you even if you have plenty of free memory. If your CPU horsepower gets oversubscribed, threads will start to thrash as the operating system switches between them to give each a fair share of timeslices. If you have too many threads trying to access a disk, the disk cache may no longer give you the performance boost that it usually does. And if your network traffic approaches the maximum possible bandwidth, collisions may impact how effectively you can use that bandwidth.
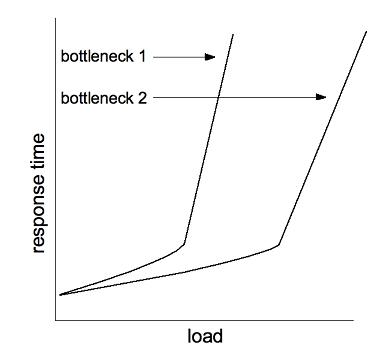 |
| Figure 2 |
When we tune the performance of the system, we try to move that knee to the right so we can handle increasing load as long as possible before the response time shoots off the scale. This tuning often happens near the scheduled end of a project when most of the system is functional enough to allow for system-level performance testing. When you improve the performance of the system, what should you anticipate to happen next? Sometimes you're still limited by the same kind of bottleneck, though the knee has moved and overall performance is better. Often, though, you'll uncover a new bottleneck that is now the limiting factor in your performance (shown in figure 2). It may be that you're now exhausting a different resource, or that a different part of the system is exhausting the same resource as before. Figure 2 shows a second bottleneck that was masked by the first one.
This is an application of "Rudy's Rutabaga Rule" from Jerry Weinberg's The Secrets of Consulting. The rule is "Once you eliminate your number one problem, number two gets a promotion." Maybe if you get enough bottlenecks out of the way, you can achieve your performance goals for your system. But don't get frustrated if each change to the system only improves performance by a small amount. Figure 3 illustrates why. (See below.)
If your system doesn't hog one resource significantly more than any other resource, then your bottlenecks will be stacked closely together. Removing each layer will only make a small improvement; you'll most likely slam into another bottleneck waiting nearby.
It Won't Go Fast if It Doesn't Go at All
Testing the system's performance tells us how fast each user can complete a task, and how many users it can support. A related concept is reliability, where we look at how long the system can operate before encountering a failure. You might want to devise a reliability test that doesn't step up the load the way a performance test often does. Not all projects do reliability testing, though, so you might be conducting performance testing before the system's reliability is solid. In that case, you'll usually find latent reliability issues in the system during performance testing. So, when you run a performance test, there's a chance that you'll encounter a failure that renders the rest of your test run invalid.
There is a random nature to most reliability issues: You will probably have more than one reliability issue in the same build of your software that can bite you during a performance test. Whether you encounter one of the latent reliability bugs and which one you see first depends on a roll of the dice. Also, be prepared for bug fixes to unmask hidden reliability bugs the same way performance bottlenecks can hide behind each other.
Another related system attribute that comes into play is robustness--the ability of the system to gracefully handle unexpected input. You can test the robustness of your software with a stress test, which may involve simply ramping up the load in a performance test until you encounter a failure. Robustness issues tend to be easier to consistently reproduce than reliability issues. If you keep hitting the same failure at the same point in your test, you probably have a robustness issue where the system doesn't respond with a reasonable error message when some system resource is completely exhausted. For example, if both your physical memory and swap space are exhausted, a request to allocate more memory will fail, and often the end user doesn't get a useful error explaining that the server is too busy to complete a requested task. Even if the system does fail gracefully, your performance test needs to watch for errors, because it's important to know if any of the simulated users didn't actually get the results they asked for.
 |
| Figure 3 |
Handling the Onion Without Tears
Here are a few tips to improve upon the typically slow progress of peeling off one bottleneck at a time.
- Consider designing and running different types of performance-test scenarios that may each identify different bottlenecks. This changes the onion-peeling process so it's somewhat more parallelized. This presumes that the system is stable enough to survive these different tests and give meaningful, correlatable results.
- Make sure your performance tests catch errors that indicate if the system isn't doing the work the test expects it to be doing (reliability or simple functional bugs). This takes a lot of extra work in most load-test tools, but it's important because failures can render your performance measurements invalid.
- Perform stress testing early in your project to identify where the hard limits are. Run the tests all the way up to system failure--i.e., run "tip-over tests."
- Balance reliability testing with performance testing. The less reliable the system, the more unpredictable your performance testing will be. If it crashes at any level of load, no matter how slight, your performance results are not meaningful. You are still on the outer skin of the onion.
The best approach is to do performance modeling hand-in-hand with performance tests that validate the model. Performance models identify bottlenecks before you even start coding. Do unit- and subsystem-level testing early in the project that covers resource allocation, performance, and reliability. Most performance issues should already be resolved before you start peeling the onion at the system level. Try using simple models like spreadsheets during design and then more sophisticated dynamic models, perhaps with the help of a commercial tool, (e.g., Hyperformix) to simulate and predict behaviors;. i.e., design for performance and reliability from the beginning to grow a smaller, fewer-layered onion. Make sure that resource allocation, performance, and reliability testing are part of unit and integration testing.


")

Lets Hang!