As a software manager at Bell Labs in 1973, I was confronted by the stress on myself and the testers who worked with me of being asked to deliver more reliable software faster and cheaper. Hence I was motivated very early to develop and deploy Software Reliability Engineering (SRE).
I will focus on the benefits of SRE for software testers in this article, but SRE also is a big help for software managers and QA staff. It involves and benefits system engineers, system architects, and developers, but I will limit myself to showing you how their roles mesh with yours.
Practically speaking, you can apply SRE to any software-based product, starting at the beginning of any release cycle.
What It Is and Why It Works
SRE is a quantitatively oriented practice for planning and guiding software development and test that meshes easily with other good processes and practices. It is based on two
pieces of quantitative information about the product: the expected relative use of its functions and its required major quality characteristics. The major quality characteristics are reliability, availability, delivery date, and lifecycle cost.
When you have characterized use, you can substantially increase development and test efficiency by focusing resources on functions in proportion to use and criticality. You also maximize test effectiveness by making test highly representative of use in the field. Increased efficiency increases the effective resource pool available to add customer value, as shown in Figure 1.

Figure 1. Increased resource pool resulting from increased development efficiency.
When you have determined the precise balance of major quality characteristics that meets user needs, you can spend your increased resource pool to carefully match them. You choose software reliability strategies to meet the objectives, based on data collected from previous projects. For example, you determine how much you will rely on system testing as compared with alternative strategies such as requirements reviews, design reviews, code reviews, and fault tolerant design. You track reliability in system test against its objective to adjust your test process and to determine when test may be terminated. The result is greater efficiency in converting resources to customer value, as shown in Figure 2.
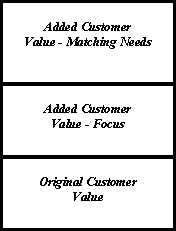
Figure 2. Increased customer value resulting from increased resource pool and better match to major quality characteristics needed by users.
SRE Process and Fone Follower Example
Let's now take a look at the SRE process. There are six principal activities, as shown in Figure 3. I show the software development process below and in parallel with the SRE process, so you can relate the activities of one to those of the other. Both processes follow spiral models, but for simplicity, I don't show the feedback paths. In the field, you collect certain data and use it to improve the SRE process for succeeding releases.
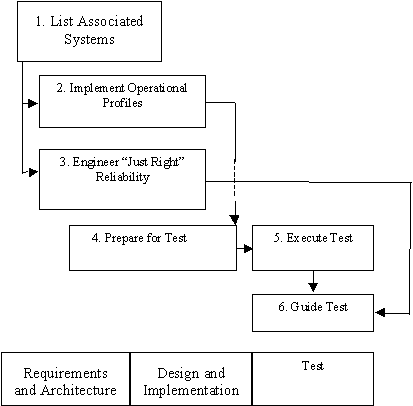
Figure 3. SRE Process
You might wonder, "Why should I, a tester, be concerned about the first three activities? They are not my job." I thought that also when I first started to apply SRE at AT&T to various projects. The answer quickly became clear: they are needed by and benefit testers the most, but they may be seen (although incorrectly) by the design engineers who have to perform them as not helping themselves directly. Rather than struggle to persuade them, we tried the innovation of including test team members on the design team. This not only worked very well, but it greatly increased the professional standing and morale of the test team. Now the test team talked with customers, had direct input into the product, felt they had a role in decision making, and no longer were in the position of the end-of-process dumping ground.
I will illustrate the SRE process with Fone Follower, an example adapted from an actual project at AT&T. I have changed the name and certain details to keep the explanation simple and protect proprietary data. Subscribers to Fone Follower call and enter, as a function of time, the phone numbers to which they want to forward their calls. Fone Follower forwards a subscriber's incoming calls (voice or fax) from the network according to the program the subscriber entered. Incomplete voice calls go to the subscriber's pager (if the subscriber has one) and then, if unanswered, to voice mail. If the subscriber does not have a pager, incomplete voice calls go directly to voice mail.
List Associated Systems
The first activity is to list all the systems associated with the product that for various reasons must be tested independently. These are generally of two types:
- base product and variations
- supersystems
Variations are versions of the base product that you design for different environments. For example, you may design a product for both Windows and Macintosh platforms. Supersystems are combinations of the base product or variations with other systems, where customers view the reliability or availability of the base product or variation as that of the combination.
Implement Operational Profiles
An operation is a major system logical task, which returns control to the system when complete. Some illustrations from Fone Follower are Phone number entry, Process fax call, and Audit a section of the phone number database. An operational profile is a complete set of operations with their probabilities of occurrence. Table 1 shows an illustration of an operational profile from Fone Follower.
When implementing SRE for the first time, some software practitioners are initially concerned about possible difficulties in determining occurrence rates. Experience indicates that this is usually not a difficult problem. Software practitioners are often not aware of all the use data that exists, as it is typically in the business side of the house. Occurrence rate data is often available or can be derived from a previous release or similar system. New products are not usually approved for development unless a business case study has been made, and this must typically estimate occurrence rates for the use of various functions to demonstrate profitability. One can collect data from the field, and if all else fails, one can usually make reasonable estimates of expected occurrence rates. In any case, even if there are errors in estimating occurrence rates, the advantage of having an operational profile far outweighs not having one at all.

Table 1. Fone Follower Operational Profile
Once you have developed the operational profile, you can employ it, along with criticality information, to allocate unit test resources among modules to cut schedules and costs. But its main use is in the system test phase, as we will see shortly.
Define "Just Right" Reliability
To define the "just right" level of reliability for a product, you must first interpret exactly what "failure" means for the product. Note that a failure is any departure of system behavior in execution from user needs; it is NOT a fault or a bug, which is a defect in system implementation that causes the failure when executed.
The second step in defining the "just right" level of reliability is to choose a common measure for all failure intensities. A failure intensity is simply the number of failures per natural or time unit. A natural unit is a unit other than time that is related to the amount of processing performed by a software-based product, such as pages of output, transactions, telephone calls, jobs, semiconductor wafers, queries, or application program interface calls. It has the advantage of being directly related to customer concerns. The common measure may be a natural unit or time unit.
Then you set the total system failure intensity objective (FIO) for each associated system. To determine an objective, you should analyze the needs and expectations of users.
For each system you are developing, you must compute a developed software FIO. You do this by subtracting the total of the expected failure intensities of all hardware and acquired software components from the system FIOs. You will use the developed software FIOs to track the reliability growth during system test of all the systems you are developing with the failure intensity to failure intensity objective (FI/FIO) ratios.
You will also apply the developed software FIOs in choosing the mix of software reliability strategies that meet these and the schedule and product cost objectives with the lowest development cost. These include strategies that are simply selected or not (requirements reviews, design reviews, and code reviews) and strategies that are selected and controlled (amount of system test, amount of fault tolerance). SRE provides guidelines and some quantitative information for the determination of this mix. However, projects can improve the process by collecting information that is particular to their environment.
Prepare For Test
The Prepare for Test activity uses the operational profiles you have developed to prepare test cases and test procedures for system test. You allocate test cases in accordance with the operational profile. For example, for the Fone Follower base product there were 500 test cases to allocate. The Process fax call operation received seventeen percent of them, or eighty-five.
After you assign test cases to operations, you specify the test cases within the operations by selecting from all the possible intraoperation choices with equal probability. The selections are usually among different sets of values of input variables associated with the operations, sets that cause different processing to occur. These sets are called equivalence classes. For example, one of the input variables for the Process fax call operation was the Forwardee (number to which the call was forwarded) and one of the equivalence classes of this input variable was Local calling area. You then select a specific value within the equivalence class so that you define a specific test case.
The test procedure is the controller that invokes test cases during execution. It uses the operational profile to determine the relative frequencies of invocation, based primarily on use but also modified to account for critical operations and for reused operations from previous releases.
Execute Test
In the Execute Test activity, you will first allocate system test time among the associated systems and types of test (feature, load, and regression).
SRE follows the usual test practice of invoking feature tests first. Feature tests execute all the new test cases of a release independently of each other, with interactions and effects of the field environment minimized. It then follows with load tests, which execute test cases simultaneously, with full interactions and all the effects of the field environment. SRE generally invokes the test cases at random times, choosing operations randomly in accord with the operational profile. And of course you will invoke a regression test after each build involving significant change. A regression test executes some or all feature tests; it is designed to reveal failures caused by faults introduced by program changes.
You identify failures, along with when they occur. The "when" can be with respect to natural units or time. This information will be used in Guide Test.
Guide Test
The last activity involves guiding the product's system test phase and release. For software that you develop, track reliability growth as you attempt to remove faults. Then you certify the supersystems, which simply involves accepting or rejecting the software in question. You also use certification test for any software that you expect customers will acceptance test.
To track reliability growth, input failure data that you collect in Execute Test to a reliability estimation program such as CASRE (for information, access
http://members.aol.com/johndmusa/CASRE.htm). Normalize the data by multiplying by the failure intensity objective in the same units. Execute this program periodically and plot the FI/FIO ratio as shown in Figure 4 for Fone Follower. If you observe a significant upward trend in this ratio, you should determine and correct the causes. The most common causes are system evolution, which may indicate poor change control, and changes in test selection probability with time, which may indicate a poor test process.
If you find you are close to your scheduled test completion date but have an FI/FIO ratio substantially greater than 0.5, you have three feasible options: defer some features or operations, rebalance your major quality characteristic objectives, or increase work hours for your organization. When the FI/FIO ratio reaches 0.5, you should consider release as long as essential documentation is complete and you have resolved outstanding high severity failures (you have removed the faults causing them).
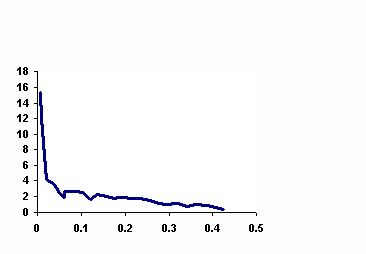
Figure 4. Plot of FI/FIO Ratio for Fone Follower
For certification test, you first normalize failure data by multiplying by the failure intensity objective. The unit "Mcalls" is millions of calls. Plot each new failure as it occurs on a reliability demonstration chart as shown in Figure 5. Note that the first two failures fall in the Continue region. This means that there is not enough data to reach an accept or reject decision. The third failure falls in the Accept region, which indicates that you can accept the software, subject to the levels of risk associated with the chart you are using.

Figure 5. Reliability Demonstration Chart Applied to Fone Follower
A Proven, Standard, Widespread Best Practice
Software reliability engineering is a proven, standard, widespread best practice. As one example of the proven benefit of SRE, AT&T applied SRE to two different releases of a switching system, International Definity PBX. Customer-reported problems decreased by a factor of ten, the system test interval decreased by a factor of two, and total development time decreased thirty percent. No serious service outages occurred in two years of deployment of thousands of systems in the field.
SRE has been an AT&T Best Current Practice since May 1991. McGraw-Hill published an SRE handbook in 1996. SRE has been a standard of the American Institute of Aeronautics and Astronautics since 1993, and IEEE standards are currently under development. There have been more than fifty published articles by users of SRE (see my website http://members.aol.com/johndmusa), and the number continues to grow. Since practitioners do not generally publish very frequently, the actual number of users is probably many times the above number.
James Tierney, in a keynote speech at the 8th International Symposium on Software Reliability Engineering, reported the results of a late 1997 survey that showed that Microsoft had applied software reliability engineering in fifty percent of its software development groups, including projects such as Windows and Word. The benefits they observed were increased test coverage, improved estimates of amount of test required, useful metrics that helped them establish ship criteria, and improved specification reviews.
SRE is highly correlated with attaining Levels 4 and 5 of the Software Engineering Institute Capability Maturity Model.
The cost of implementing SRE is small. There is an investment cost of not more than three equivalent staff days per person in an organization, which includes a two-day course for everyone and planning with a much smaller number. The operating cost over the project lifecycle typically varies from 0.1 to 3 percent of total project cost. The schedule impact of SRE is minimal, since most SRE activities involve only a small effort that can parallel other software development work. The only significant critical path activity is two days of training.
Conclusion
If you apply SRE in all the software-based products you test, you will be controlling the process rather than it controlling you. You will find that you can be confident of the reliability and availability of the products you release. At the same time, you will deliver
them in minimum time and cost for those levels of reliability and availability. You will have maximized your efficiency in satisfying your customers' needs. This is a vital skill to possess if you are to be competitive in today's marketplace.
Further Resources"
Course for practitioners:More Reliable Software Faster and Cheaper-two days (onsite or public)-conducted by John D. Musa.
Software Reliability Engineering by John D. Musa. This book is a very practitioner-oriented, systematic, thorough, up-to-date presentation of SRE practice. It includes more than 350 frequently asked questions.
More Reliable Software Faster and Cheaper (Software Reliability Engineering) Web site. Short and long overviews, bibliography of articles by software reliability engineering users, course information and announcements, consulting information, deployment advice, Question of the Month.

")

Lets Hang!