Three of the Agile Manifesto's twelve principles reference the value of producing working software. It directly names working software as the highest priority—a deliverable to be completed often and the primary measure of success. Scrum practitioners should note the goal of every single sprint is to complete "production ready" code. The point to teams is clear: Agile teams should endeavor to deliver working software capable of rapid deployment on a regular basis. The message to stakeholders is also clear: If you see it in a demo, you can quickly put it in your production environment. But, what happens if that's not quite the case?
 Done, Done, DONE
Done, Done, DONE
I saw it on my first Scrum team. This particular challenge expressed itself clearly on our little task board. We started with three columns representing the states of work of a given story: "Not started," "In process," and "Done." It seemed innocent enough and I was enamored with the elegance of such a lightweight framework. How was I to know what would come next? The problems began when we neared a release and started integrating our work with another team. Inter-team dependencies began to bring the system down. When system administrators tried to move the code to new environments, incomplete release notes caused havoc. Additionally, upstream data sources weren't receiving changes propagated on the same schedule as our team.
Our ScrumMaster tried to hold us accountable by asking us what "done" meant. The far right column of our board was changed to "Done, Done," implying our standard definition of done was just not good enough. Although this change to our board was half in jest, it was an indication of our failure to account for cross-team integration. It got worse. Later, we found that even though the business signed off on our stories, they weren't fully approved. The system people voiced major performance concerns when they saw just how often we were going to call some of the internal services. It seems that "Done, Done" wasn't actually good enough for us, either; we had to update our board to read, "Done, Done, DONE." I think we would have kept doing this as we discovered additional requirements to actually launch our product. Mercifully, by this point, we ran out of real estate on our humble rolling whiteboard; however, the impact to the team was not over. In the end, we spent nearly two months preparing for a production roll out. The team’s speed of delivering new features plummeted as we dug through the "Done" and merely "Done, Done" work fixing bugs, writing release notes, and changing configuration files to move through our environments. Our business sponsor was not pleased with two months of additional work for functionality she believed was already complete.
So what was at work here? Every day, senior developers and testers worked together in our team. We felt our code was bulletproof and our product owner was signing off on each story as we went. In my experience, there are two primary culprits at play in situations like this that conspire to undermine the team's ability to realize "potentially shippable" code. These culprits have many manifestations; but let's take a look at some of the most common instances of both.
You Be Agile While I Stay the Same
As an agile consultant, I should fess up. My profession bears a burden for one of the biggest problems encountered in agile adoptions. In our earnest desire to help get buy-in within an organization, we invariably highlight the benefits. All it takes is one slightly overeager evangelist to make agile sound a little too close to a silver bullet, and all of a sudden it is perceived as this magical thing that is going to simply plug into your organization, make development teams run faster with higher quality, and in no way impact other parts of the organization. This is probably further exacerbated by the small nature of agile teams—generally around seven people—that they do not include release engineers, system administrators, or other specialized experts whose expertise is in short demand. In the old world, they were integrated through a linear process: Architects became involved during analysis and release engineers came in during preparation for launch for example.
Agile projects can unify separate groups. The product owner can change the relationship between the business and technology by bringing someone into the team who represents the customer’s voice. Unfortunately, not all interests can be folded into the process. When teams experience trouble, release engineering is a great solution. Chances are a Scrum team is working in an environment where team members have administrative rights. Even if they are using a continuous integration or other automated build process, there is likely a great deal of variance from what a production deployment looks like, and it does not involve the people who will actually be moving the code into a production environment.
Thus, the project moves along nicely with team members thinking they could deploy their code to production any time they want. Only later do they realize they have no release notes, their configuration settings are unable to port from multiple environments, and the system administrators have no idea how the new system works. All of a sudden, a simple production release turns into weeks of debugging, documenting, and supporting people who are trying to rapidly learn about a system they didn't see until they were asked to deploy it into a production environment.
This concept has an infinite number of permutations: The upstream system managed in a traditional waterfall process that will supposedly be ready just in time to integrate, the performance team that only checks the application's performance at the end of the release, and the support team that doesn't familiarize itself with the application until shortly before launch. All of these items are examples of people on the boundary of an agile project who can cause catastrophic problems if they are not aligned with the team's activity. This is, of course, easier said than done.
I have seen teams invite these groups to their semi-weekly demonstrations, try to elicit requirements from them, and even go so far as open up environments to them in order to get feedback. Some stakeholders take advantage of these opportunities, but I have also seen many stakeholders request to know when the product will launch, and then disengage until shortly before that date. The specifics of these situations vary, but the net impact is the same. The businesses see their application mature while receiving a sense of the completion rate. They become confident and trust the team as they see features complete at a nice rate, and they may even say good things about agile. However, as they are excited and prepared for the big launch date, things go horribly awry. The actual implementation is that final moment of accountability when all that work that was only "Done, Done" is shown to be not completely ready. In good cases, the team learns a valuable lesson and starts adding more to its definition of done. In bad cases, someone asserts, "This happened because we didn't have good requirements and design up front," and somewhere an agile initiative dies.
Software Is Incredibly Expensive Inventory
Recently, I was in a local office supply store where I saw a four gigabyte flash drive on sale between the gum and candy next to the check out register. For about ten dollars I could purchase sufficient capacity to store all the work of a team in a device that would fit on my keychain. At first blush, it appears that the intangible nature of software and the low cost of storage means that inventory doesn't matter in software development. This is a seductive idea, and, unfortunately, today's configuration management tools only make matters worse. While this is not inherently bad, it makes the cost of branching so low people may ensconce themselves in their own environment.
Modern configuration management tools allow every developer to have his own branch of code so that he doesn't need to coordinate with others. The ease of branching means there are hardly any problems when I find another piece of code checked out—I simply add a branch and keep going. In fact, if we combine this with the rapidly growing number and increasing capability of local sandbox environments available to developers, I can develop entirely on my own—or within my team—oblivious to anything outside my immediate area.
If our first challenge involved how easy it is for other groups to deal with an agile team in a traditional way, this challenge involves technology making it too easy for development teams to silo themselves off from the world, and even each other. The development team accumulates massive amounts of work in process that has not been integrated into a product. This may seem fine; after all, we have an enterprise configuration management tool to deal with things like this. The problem is that we don't appreciate how expensive it is to carry all this work in process.
Any piece of functionality has a huge amount of context specific information that exists in the heads of the developers and customers who articulated what they want. The longer this code sits in some unvalidated state, the more we risk losing some of that information, and the more expensive it becomes to retrieve it. There is a profound difference between finding a bug the day after a developer wrote it and finding it a month later. In the former instance, the QA engineer can point out the issue to the developer and see it fixed that same day. In the later situation, the bug must be more carefully documented. As a month of work has gone by, there may be some uncertainty about exactly who introduced the bug and when that took place. People may not recall the precise functionality or all the changes made in that time. Testers in this situation may find themselves with orphaned bugs trying to figure out where it got introduced to the system so that someone can fix it.
The further we get from construction and validation, the more difficult this becomes. In traditional projects, teams try to surmount this challenge with documentation, and many agile teams embark on the same effort. Now they impose the cost of documentation on the developers, further slowing down the delivery of features and increasing the space between development and validation. It also introduces the cost of maintaining more documents and the challenge of conflict. When a design document, test case, and code do not match up, which one is the source of truth?
So, when we put these two challenges together, we find that many outside groups may be happy to treat an agile team like any other team and anticipate for a linear product delivery according to a traditional delivery schedule of six to eighteen months. This blends with the ability of modern software development teams to develop and run their own instances of a system, and, in some ways, we are not far from the prototypes of an earlier generation of software development. Customers can see the features, but they can't really experience them, yet. What they are seeing is a simplified implementation or something that has not yet been proven through an organization's delivery process. This results in a hidden reserve of undone work that will be a business liability when the organization finally gives the green light to launch. The organization may find an array of unexpected issues, which never showed up during conference room demonstrations throughout the project.
If Something Hurts, Do It Often
Agile projects are fundamentally learning endeavors based on the concept that a team can receive the necessary feedback and insight to build the right product in the right way if it expands its own boundaries of understanding. Following that convention, there is a truism within the field that projects should confront their big issues early and often or, as some would say: "If something hurts, do it often."
If staging a release through our deployment process is painful and lengthy, we should keep doing it. We should do it more often so that we get good at it and it is no longer an impediment. We should do this to prevent the situations described earlier. Avoiding pain not only harms our project outcomes but it also creates a false sense of confidence. Avoidance lulls people into a sense that everything is going well when, in fact, there is massive unexposed risk buried in the project. It not only denies the organization a real opportunity to improve its operations but it is also a reckless way to deal with our customer's money.
So, what exactly are we putting off in those situations described above? We are not moving entirely through the value stream. Value stream analysis is a lean concept used for measuring and illuminating all of the steps required to take an idea and turn it into a valuable product or service. Failing to understand the full process and optimizing on a smaller part of that stream can undermine delivery. This is similar to when I worked with the agile team that was able to rapidly turn out functionality in a controlled environment, but became bogged down when going through an integration and release process.

The figure above illustrates the challenge that faces many teams. In our hypothetical example, there are six distinct steps that must occur for the team to deliver value, beginning with a customer explaining the requirements and ending with the configuration of the application after its release into a production environment. The team committed to two week iterations and demonstrated functionality to its customer after completing testing, calling that "potentially shippable" product. However, the work must go through two more steps in order for the organization to realize value. If the team is communicating its velocity based on its ability to move functionality through the first few steps, then we have no insight into how long it takes to do the actual release or the post-configuration launch. These steps may not require much work, but until we move through them, we won't actually know. Of course, many teams will face a technical or business limitation preventing them from frequently implementing their code to production. So, teams may need to incorporate release-like activities into their iteration.
A team may decide that its work is done once it has been successfully deployed to a controlled environment by the release engineering group responsible for a production deployment. In the figure below, the team has a staged environment where tested code is deployed and configured, thereby validating the deployment and configuration process in an environment approximating what will be done in production. In this scenario, the team's code will go through a deployment process every iteration, ensuring that release engineering and other support groups had an opportunity once every couple of weeks to get familiar with the deployment process.

Visualizing the Value Stream
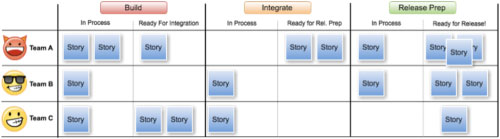
Sometimes, teams are unable to bring the additional work of deployment into a short, timeboxed iteration. The availability of release engineering may preclude such a quick turnaround. In these situations, teams may wish to use something akin to a kanban board in order to manage the work moving through a deployment process. The figure below shows how such a board could be used to manage the work across three teams.
Simple Is Beautiful
Having walked through a couple of ways to manage the complexity of large releases and dependencies within projects, we should discuss the simplest—but sometimes most difficult—strategy: Reducing the complexity of releases by making them smaller. As described earlier, the more in-process work in the system, the higher the carrying cost. We can visualize this process and stage deployments, but it's simpler to have frequent, small releases. Techniques like bolstering a definition of done to include deployment and visually mapping the production preparations steps should not be used as crutches for supporting excessively large releases.
Looking back at that first agile project, I would have probably gone further to confront our challenges. We labored for more than nine months before trying a release, and only then did we realize how difficult it was for us to get to that elusive production environment. Unfortunately, by that time expectations were established and our sponsor was disappointed when those expectations were not met. If we attempted to release something after only three months, it would have been a mess, but we would have had time to recover, establish more realistic expectations, and deal with numerous newly discovered stakeholders.





Lets Hang!