You may already be using code-coverage tools to quantify application testing and to identify untested portions of your code. These tools automatically instrument your code to provide detailed information about dynamic application behavior. You may also be using optimizing compilers (static or just-in-time) that are specialized for particular microprocessors. Increasingly, these compilers also measure dynamic application behavior and use the measurements to improve optimization.
In practice, coverage tools and optimizing compilers use similar instrumentation mechanisms. Because of this overlap, code coverage analysis will soon be an integral part of optimizing compilers and will be provided as an option by major vendors. This will simplify software development and testing by eliminating potential differences between the way compilers and coverage tools interpret code. It will also reduce compiler overhead for collecting coverage profile information because a compiler can more effectively optimize code it has instrumented itself. Finally, the uniform coverage information will help you accelerate testing cycles by enabling you to prioritize your regression tests and run the most relevant tests first.
Why Optimizing Compilers Need Coverage Profiles
In many cases, you can improve an application’s performance by monitoring its typical behavior and then allowing an optimizing compiler to re-optimize the code based on the application profile. This is called profile-guided optimization (PGO) and it has been shown to deliver significant performance gains for large-scale commercial database applications as well as performance benchmarks.
There are several reasons for the effectiveness of PGO. First, certain architectural and micro-architectural features of modern processors — instruction caches, branch prediction, TLB management, etc. — can be used more effectively when the typical behavior of the application is understood. Second, dynamic profile information identifies which regions of code are performance-critical. The compiler can then generate specialized and optimized code along the critical path of the application to deliver a very high performance.
In the following sections, we look at several of the most effective optimizations performed by profile-guided optimizing compilers such as code flayout optimizations. We also discuss function inlining and virtual function dispatch optimizations, both of which are especially effective for object-oriented programs such as C++ and Java.
Code Layout Optimizations
Code- ayout optimizations include basic-block ordering, function layout, and function splitting. The main idea is to put related components of code close to each other. This generally helps to reduce branch mispredictions, instruction-cache misses, and paging traffic.
Basic-Block Ordering
If a compiler lacks profiling information, it will typically place basic blocks in the same order they are found in the source code, possibly with some additional syntactic heuristics to enhance performance. A better approach is to order blocks to reduce the frequency of jumps. However, without profiling information, it is often impossible to accurately predict the most likely outcome of conditional statements at compile time.
Modern microprocessors employ sophisticated multilevel branch-prediction mechanisms, which partially compensate for inefficient block ordering. The history of branch outcomes is recorded in a special type of cache, called the branch-target buffer (BTB), which is implemented in silicon. The information in the buffer is used to dynamically predict the outcome of branches, so the microprocessor can execute the predicted code speculatively. Depending on the number of branches and the accuracy of branch predictions, this can substantially improve performance.
The size of the BTB is constrained by economic issues, which limits the number of branch outcomes that can be recorded. For example, if a processor has 1024 BTB entries, it will record the outcome of the last distinct 1024 branch instructions that were executed. If the critical path of the application contains a lot more than 1024 dynamic branches, the processor may experience frequent BTB misses. In this case, the processor usually resorts to heuristic rules for predicting the outcome, which are generally less accurate than BTB data. For example, the processor might assume that forward branches (jumps to a higher address) should be taken and backward branches (jumps to a lower address) should not.
You can improve the success rate of branch prediction by using an optimizing compiler that takes advantage of profile feedback. Using the profile information, the compiler can lay out basic blocks so that branches are predicted more accurately. It can also establish fall-back heuristic rules that will more reliably guide the processor in the right direction.
Figures 1 through 4 show how code layout can impact processor performance. The sample code is shown in Figure 1. Figure 3 shows how a conventional compiler might lay out the generated code. You can see that the basic-block layout in Figure 3 follows the natural syntactic order of the blocks of code as they are shown in Figure 1.
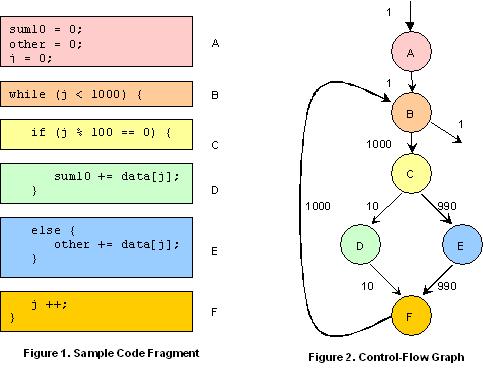
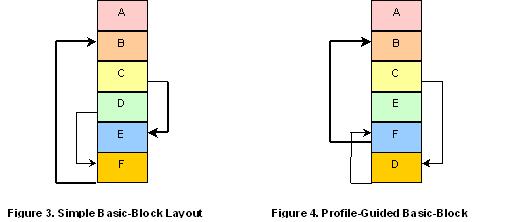
A control-flow graph of the code is shown in Figure 2. The numbers indicate the typical flow for 1000 branching events. Based on these numbers, it is clear that the critical path of this code fragment is the cycle B->C->E->F->B. The control transfers from B to C and from E to F do not need any branch instructions because the simple basic-block layout already has B adjacent to C and E adjacent to F (Figure 3). However, the branches from C to E and from F to B do need explicit branch instructions. The critical path of the code in Figure 3 therefore includes two branch instructions for these control transfers.
To improve performance, an optimizing compiler using dynamic profile information might layout the code as shown in Figure 4. With this layout, the critical path of the code now includes only one branch instruction, the transfer from F to B. This reduces the critical-path length of the code for faster throughput. It also reduces the load on the BTB, because the processor effectively needs to remember the outcome of only one branch instruction. For an application with many branches, reducing the load on the BTB can translate into fewer missed branch predictions, which further accelerates performance.
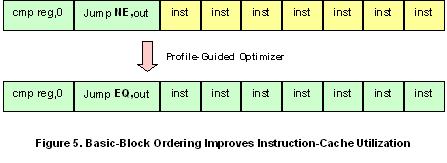
A profile-guided optimizing compiler can also use basic-block ordering to significantly improve the utilization of instruction-cache. When the processor fetches an instruction from memory, it typically fetches an entire line of code and stores the line in instruction-cache for faster retrieval when needed. However, the processor may only need a single instruction from the cached line of code. This will be the case if the relevant instruction is an unconditional jump (or a conditional jump with a satisfied condition). This is an inefficient use of instruction-cache, because only a part of the fetched line of code is used.
As shown in Figure 5, basic-block ordering based on dynamic profile information can be used to improve instruction-cache utilization. The instructions colored in green are executed; the instructions in yellow are not. Of course, as shown in this example, the compiler may have to adjust the branch instructions. (In this case, it inverts the condition of the jump instruction.)
Function Layout
Function-layout is very similar to basic-block ordering and may also deliver substantial performance enhancements for your code. While basic-block ordering attempts to minimize branch misprediction and instruction-cache misses, function layout reduces paging traffic and minimizes page faults. Processors have a limited number of translation lookaside buffers (TLBs) to handle virtual pages that are present in real memory. A TLB miss is typically very expensive, often costing thousands of instructions.
Function layout based on dynamic profile information has proven to be extremely effective in minimizing TLB misses and reducing page faults. In this approach, the compiler takes advantage of the metrics provided in the call graph of the associated program functions. (See Figure 6b.) The nodes of the call graph represent the functions of the program, while the edges represent a possible calling. The numbers on the edges indicate the number of times the caller function has called the callee function, possibly from various points. Using this information, the compiler can lay out functions to optimize performance for the most common function calls.
Function Splitting
In addition to function layout, profile information enables a compiler to perform function splitting. In this process, function code is partitioned into hot and cold regions based on frequency of execution. The cold partition consists of code that is rarely executed, such as exception case handling code. The hot partition consists of frequently used code. The goal of function splitting is to put as much hot code as possible on the same page, so that the working set of frequently-used functions is covered by a small number of pages. This technique can be very effective in improving the performance of large-scale integer applications such as database servers.
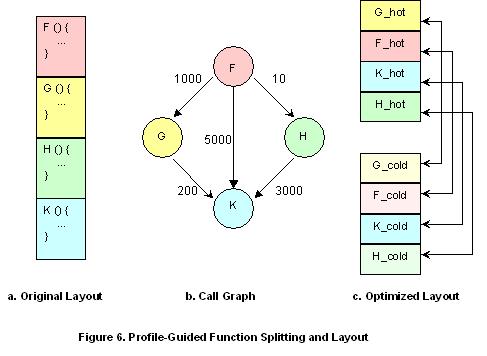
Figure 6 shows you how code-splitting based on profile information is applied in a hypothetical case. The original function layout is shown in 6a. The numbers in the call graph (6b) represent call frequencies and are used by the optimizing compiler to apply function splitting and function ordering (6c). As you can see in the optimized layout, the compiler not only partitions hot and cold functions, but also tries to put function pairs that share high frequency calls very close together (F/G, F/K, and H/K). Function splitting can also help to reduce paging traffic by minimizing the number of pages required to support critical paths.
Code Specialization
Code specialization is another broad class of compiler optimizations that can be used with profile information to improve performance for your applications. In these optimizations, generic code on the critical path of the application is specialized to improve performance for a particular instance. Examples of code specialization include function inlining, partial inlining, type-feedback, and generalized strength reduction.
Function Inlining
In function inlining, the body of a called function is placed directly in the critical path of the application, while the semantics of parameter passing are preserved. This eliminates the overhead of function calls. It also makes it possible to optimize the inlined code within the context of the specific function call. Of course, function inlining typically increases overall code size, because multiple copies of the same code are generated for various instances. These increases in code size can result in more instruction-cache misses and page faults, which can degrade overall performance. (In some cases, function inlining can actually decrease code size, such as when a static function is called just once and can therefore be highly optimized within the context of the single caller.)
Function inlining should be used selectively to be sure performance benefits outweigh the impact of code size increases. Profile information can be especially useful in this respect. By knowing the frequency of calls for a specific function, the compiler can determine whether inlining will have a positive overall impact for each instance. The compiler can also use profile information to identify the critical path of called functions. It can then inline only the critical part of the function. If this is done, the compiler needs to provide the necessary mechanism for jumping to the non-critical parts of the function when required.
An optimizing compiler can also use profile information to implement function cloning. In this technique, the compiler creates multiple clones of the same function. Each clone is specialized for a particular context, and the compiler must ensure that the right clone is called for each context. Function cloning provides a middle ground between full inlining and no inlining.
Indirect Function Calls
Profile information can also enable a compiler to optimize indirect function calls in traditional languages such as C, as well as dynamically dispatched function calls in object-oriented languages such as C++ and Java. Virtual functions usually are small in size, so the overhead of the function call (e.g., saving and restoring registers) is comparable to the cost of executing the function body. Performance often can be improved by inlining the function to eliminate the function-call overhead.
However, with an indirect or a virtual function call, it is often impossible to decide the target of the function call at compile time. For an indirect call, the container of the address of the function may have different values at different execution times. For a virtual function call, the corresponding class may be sub-classed during runtime, in which case a new definition may override the previous definition of the function of the super-class.
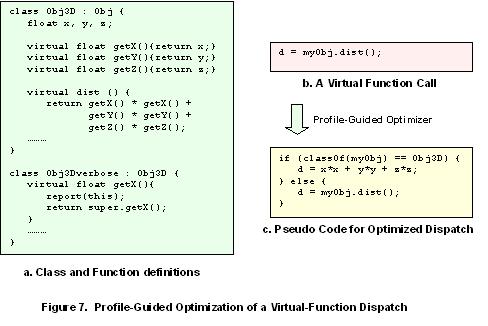
Because of these issues, the compiler cannot inline virtual and indirect function calls without adding the necessary checks. Here again, profile information can be useful. If metrics show that the target of the function call is a particular function most of the time, it may be beneficial to inline, partially inline, or specialize that function. The compiler can then generate the code to check the indirect or virtual call against the dominant value. This optimizes the path for the most common occurrence. For other occurrences, the call will be dispatched indirectly as in the non-optimized code. See Figure 7 for an example of this type of optimization.
Accuracy and Efficiency of Collecting Coverage Information
So far, we've discussed the substantial advantages of using profile information to enhance the benefits of an optimizing compiler. There are also key advantages to having the code coverage tool tightly integrated with the compiler. In particular, a compiler is capable of producing more accurate coverage information than an external tool for the following reasons:
- When compiling complicated conditional expressions, the compiler is free to apply safe and semantics-preserving optimizations that short cut the predicates. In other words, a line-coverage tool may consider a source line as covered while, in fact, only some parts of the expressions in that particular line have been covered.
- Because it is the compiler that generates executable code, it can tell you precisely which parts of your code were not covered by the application tests.
- Compilers always lead external coverage tools in recognizing and properly handling language extensions.
- There might be a difference between the way a compiler front-end interprets a given set of code and the way a coverage tool views that same code. For large-scale applications, building application code can be a major challenge, and there is always a chance that the binaries generated through external instrumentation or compilation of the application by a coverage tool may not function properly — particularly with uninstrumented binaries. Exception handling typically complicates the problem even further.
In addition to better accuracy, we have found that the optimized performance of compiler-instrumented binaries is always significantly better than that of binaries that have been instrumented using external coverage tools. If you have a QA environment in which a normal cycle of regression tests keeps hundreds of computing systems busy for several days, this performance advantage can be an important benefit.
There are two key reasons why compiler-instrumented binaries deliver better performance. First, instrumentation probes inserted by coverage tools are often implemented using procedure calls, to hide the complexity of bookkeeping. The overhead of these procedure calls and returns can become significant, since an extra function call must be inserted for every branch or condition in the source code. Second, it can be very difficult for a compiler to determine the side effects of these externally inserted function calls. This can prevent the compiler from implementing certain optimizations. As an example, common sub-expression elimination and register allocation are two major compiler optimizations. Both are negatively affected by conservative assumptions about side effects. In contrast, when the compiler does the instrumentation, it can inline the probes and understand the side effects with almost no analysis required.
Presentation of Coverage Information
The computing industry is seeing a widespread move toward distributed software development environments including offshore outsourcing to reduce costs. This strategy requires that dispersed groups share the same source base for development, testing, and validation, typically using an intranet. We recommend a distributed, Web-based architecture for supporting these geographically divided development teams. Such an approach is more efficient than the extremely large and monolithic data files used by traditional coverage tools. Proven standards, such as HTML and XML, support flexible access to distributed information from static pages to dynamically generated queries to databases.
Web technologies also support efficient linking and controlled access to various types of data. For example, if you need to investigate code coverage for certain components, you no longer have to access or download the entire coverage data. You can simply use a standard browser to view your source code annotated with coverage properties. You can then submit queries for finding tests that satisfy your coverage criteria. By storing the coverage information in a database, you can track changes in coverage metrics to identify trends, investigate the coverage impact of newly added code, and differentiate the coverage properties of different test suites and workloads.
About the Authors
Mohammad Haghighat is a principal engineer at Intel Corp. He has been with Intel since 1995 and is the architect of Intel Compiler's profile-guided testing tools. He has a Ph.D. in computer science from the University of Illinois at Urbana-Champaign and has published a book on Symbolic Analysis for Parallelizing Compilers.
David Sehr received his Ph.D. from the University of Illinois at Urbana-Champaign. He has been a member of the Intel Compiler team since 1992. He is currently co-architect of the Intel Compiler and is leading a small team responsible for infrastructure and advanced development.


")

Lets Hang!