Summary
This article relates the benefits of data-driven testing. It will describe how we approached data-driven testing with SILKTest, what tools we used to generate the data, and the results.
This article relates the benefits of data-driven testing. It will describe how we approached data-driven testing with SILKTest, what tools we used to generate the data, and the results.
As Director of QA for an Internet start-up, DoDots (Sunnyvale, CA) one of the first things I considered after staffing our QA department was the selection of an automated test tool and test automation approach. The test tool selection was, of course, SilkTest (a no-brainer in my humble opinion). After some debate, the team agreed our automation test approach would employ heavy use of data-driven testing. I have been an advocate of data-driven testing back when I first started using SilkTest (QA Partner) about 6 years ago. The benefits of data-driven testing are many, I'll discuss a few approaches we used, but one of the initial impediments to the deployment of any large scale data-driven testing is the test data itself. Namely, how and where could we acquire realistic data, and lots of it, for use in our Silk scripts? In this article, I'll describe how we approached data-driven testing with SilkTest, what tool we used to generate the data, and the results of our efforts.
Data-Driven Testing
Segue documentation for SilkTest and QA Partner has always advocated the use of data-driven testing. In my opinion, the decoupling of data from the test script allows QA organizations to employ a very effective testing strategy based on Equvilency Classes or Equvilency Partitioning.
With this approach, the data can be grouped into ‘classes’. The classes can then represent various test conditions: Valid, Error, Boundary, and others. The data can be interchanged by simply changing a single line in your Silk test scripts (usually the file path variable). For example, we needed to create large numbers of new users and passwords. We created 'classes' of users based on the requirements for username and password. Some of these users had valid usernames but invalid passwords, other users had valid passwords but usernames exceeding the defined limit or containing illegal characters. Finally, we had lots of users whose passwords and usernames were just fine.
You may be reading this and asking yourself–so, what’s the big deal? Nothing I've written so far is really new or groundbreaking for experienced SilkTest users. Fair enough. The real purpose of my article is to describe how quickly and easily we were able to generate thousands of unique datatypes for use with our Silk scripts.
The Data
As I mentioned earlier, the real challenge of data-driven testing is the data itself. DoDots required that we test our database schema under very large loads. The load testing requirements for just the usernames and passwords were in the thousands. In order to meet these testing requirements and our deadlines we needed a way to create large data sets quickly.
For our solution, we chose to use data generating software. There are a number of data generators on the market. With few exceptions, all of them share two basic features: generating data directly to database tables (usually via ODBC) and generating data to flat, ASCII text files. We evaluated three of these data generators and found one of them, Datatect, by Banner Software to have features that are aimed directly at SilkTest users.
I had used an earlier version of Datatect for data generation at Network Associates a few years ago and found the tool performed equally well when generating data to databases or flat files. The only real drawback, for SilkTest, was the required flat file 'post-processing' needed in order to format the data text file for use with SilkTest's various File handling methods. However, the newest version, Datatect 1.6, has a whole new set of features that allowed us to create data-driven SilkTest scripts that were almost 'plug-in-play'
The Data Generator
Datatect 1.6 has a simple and clean user interface. As shown in Fig 1., the main screen is composed of 9 tabs. The first three are used to create Datatect Specifications (more on this later) and the remaining 6 tabs are used to create Datatect Definitions.
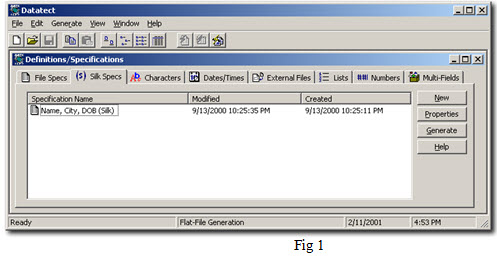
Basically, a definition is a user-defined or built-in data type with one of the following characteristics: Characters (proper names, addresses, phone numbers, etc.), Numbers (Integers, decimals), Dates/Times, Lists (user-defined), and Multi-Fields (combinations of built-in and user-defined types).
Borrowing from my earlier username/password example, we created a Datatect 'Username' defintion using the Character tab. The screen shot in Fig. 2 shows the selections we made in this dialog for user names.
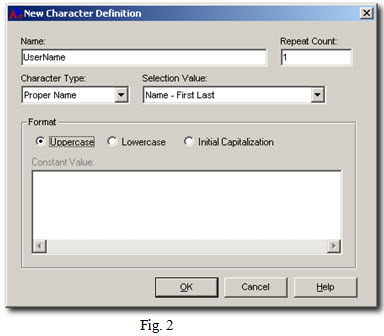
For our passwords, we first created two more definitions: a Number (unique random), and another Character (alphanumeric). We then combined these two definitions using a Datatect Multi-Field definition so that our passwords would contain a mix of characters and numbers and, most importantly, they would be unique.
After creating our definitions, the next step was to create a Datatect SilkTest specification to output the results of our data generation. This is where Datatect really shines for SilkTest users. Due to various confidentiality and trademark issues regarding DoDots intellectual property, I will illustrate this feature using the default Green Mountain Outpost (GMO) specification provided by Datatect
In Fig. 3, you can see the SilkTest output specification for the GMO application. On the left side, highlighted in blue, is the field "BillName".
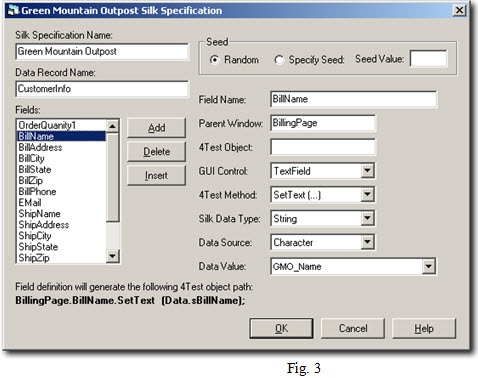
To the right, you will find the various parameters you set according to the type of GUI control (Textfield, Checkbox, Combobox, ListBox, PopupList, and RadioList) under test, the 4Test method required to input the data into the GUI control, the SilkTest data type (String, Real, Number, Integer, Boolean, Enumeration, Time, and Date), and the Data Source/Value (Datatect definition).
In the lower left, Datatect provides a preview (in bold) of exactly how it will generate the 4Test code to input data for the RECORD variable "BillName". Not only will Datatect generate the data text file, perfectly formatted for use in any SilkTest data-driven test case but it will also generate, if you choose, all of the 4Test code required to process each field in the data file. You simply click the Generate button in the Silk tab of Datatect, provide a name for the data output file and then click the checkbox labeled ‘Generate Silk 4Test Code’ and Datatect does the rest. It creates a ".dat" data file and uses the same name to create a corresponding ".t" script containing the 4Test code.
Before we purchased Datatect, I tested the default Datatect GMO specification to generate the evaluation limit of 25 records and the 4Test code needed to create customer orders on the Segue GMO website. I needed to add a total of 5 lines of 4Test code to the 4Test script generated by Datatect in order to compile and run the script. Datatect created the 4Test RECORD structure and all the fields, the file handle and file processing code, the testcase, the while loop used to parse each record in the data file, various comment blocks, and almost all the 4Test code needed to input each data value into their respective fields in the various GMO forms found on Segue’s website.
The Results
Using SilkTest and Datatect, the QA team was able to create dozens of data files (containing thousands of records) based on our established equivalency classes for testing the DoDots application. There were also two rather unexpected side effects from our data generation efforts.
One of the first things I noticed was how the 4Test code generated by Datatect actually helped some of the QA team's junior personnel make the jump from the 'capture, record, playback' methods to the more advanced programming techniques required to make SilkTest scripts robust in a test production environment. They began to experiment with different ways to use Silk's data-driven testing capabilities, confident that Datatect would generate most of what they needed.
The second thing that I noticed was how some of the senior SilkTest users had come to rely on the table generation capabilities of Datatect to effectively reverse engineer our database schema. They were using Datatect Specifications to examine the schema of each table and the data type of each field so they would know exactly what data type to create for SilkTest scripts. That was a very pleasant surprise even for a battle-worn QA guy like me.
Lets Hang!