Why the traditional playbook fails, and how to measure what matters.
We instrumented an internal document summarization service with full latency histograms (p50, p95, p99) and it looked solid under load. In production, users reported wildly inconsistent response times; our test corpus used uniform short documents, but production requests included lengthy contracts generating 10x more tokens. Our load test had been benchmarking a system that didn't exist.
Performance engineering has a well-established playbook. Measure response times. Identify percentiles. Load test until something breaks. Find the bottleneck. Optimize. Repeat.
That playbook assumes you control the system you're testing. With LLM integrations, that control is an illusion. The model inference, often the dominant factor in response time, is a black-box operated by someone else, subject to their capacity constraints, their rate limits, their pricing. You can't optimize it. You can't even reliably predict it.
For agentic systems, the challenge compounds. An agent might execute three steps or thirty. Response time isn't a number. It's a distribution with a long tail you can't truncate. Traditional SLOs don't map to systems with variable-length execution paths.
This isn't a reason to abandon performance engineering. It's a reason to redefine what we're measuring and what we're optimizing.
Latency Becomes Multi-Dimensional
Traditional API latency is a single number: time from request to response. LLM latency fragments into components that matter differently depending on user context.
Time-to-first-token (TTFT) determines perceived responsiveness. Users waiting for a streaming response judge speed by when characters start appearing, not when the full response completes. A system that delivers the first token in 200ms feels faster than one that delivers a complete response in 800ms, even if total completion time is identical.
Inter-token latency (ITL)—the time between successive tokens during streaming— determines perceived smoothness. A system with good TTFT but high ITL creates a stuttering experience where characters appear in uneven bursts. Users notice the rhythm of delivery, not just when the first token arrives.
Tokens-per-second (TPS) governs the streaming experience. Too slow, and users read faster than content appears, creating frustrating pauses. Too variable, and the output stutters. Consistent token rate matters more than peak throughput.
Total completion time varies dramatically with output length. A 50-token response and a 500-token response have fundamentally different performance characteristics from the same model. Your latency distribution depends on your output distribution, which depends on your prompts, your use case, and your users.
The architectural implication: you need separate SLOs for each dimension. A p95 target for total response time doesn't capture whether your users perceive the system as fast. TTFT p95 might be the metric that actually correlates with user satisfaction, but it's not what most teams measure.
Speed × Cost × Quality: The Optimization Surface
Traditional performance optimization has one axis: make it faster. LLM performance optimization has three: speed, cost, and output quality. They trade against each other in ways that make single-metric optimization dangerous.
Consider your options for reducing latency. You could use a smaller, faster model, but quality degrades. You could reduce max tokens, but truncate potentially important content. You could cache aggressively, but serve stale responses. You could parallelize requests, but multiply costs. Every latency optimization has a cost or quality consequence.
The same applies in reverse. Optimizing for cost pushes you toward smaller models, shorter contexts, aggressive caching, all with latency and quality implications. Optimizing for quality pulls toward larger models, longer contexts, multiple inference passes, exploding both cost and latency.
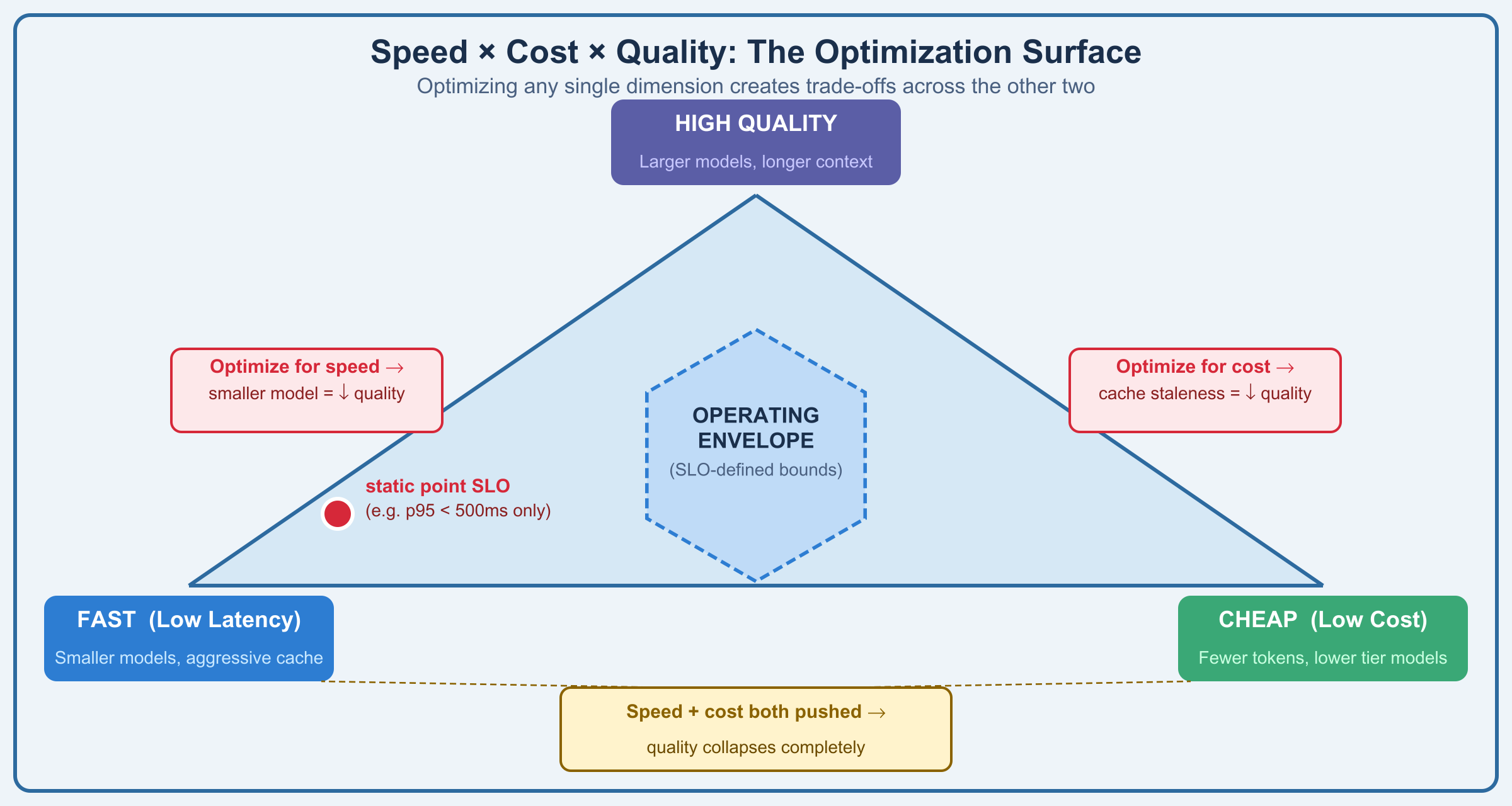
Performance testing must capture all three dimensions. A benchmark that only measures requests-per-second tells you nothing useful. You need: latency at target throughput, cost-per-request at target quality, quality metrics at target latency. These form a surface, not a point. Your SLOs must define an allowable operating envelope on that surface, rather than a static point
Load Testing What You Actually Own
Here's the uncomfortable truth about load testing LLM systems: you can't. Not in the traditional sense.
Rate limits cap your maximum throughput. API costs make sustained load prohibitive. A serious load test against GPT-4 can cost thousands of dollars. The model provider's infrastructure determines performance characteristics you can't influence. When you load test, you're mostly measuring their capacity, not your system's.
So what can you performance test? Everything around the model call. The "Application Envelope": the components you own, operate, and can optimize.
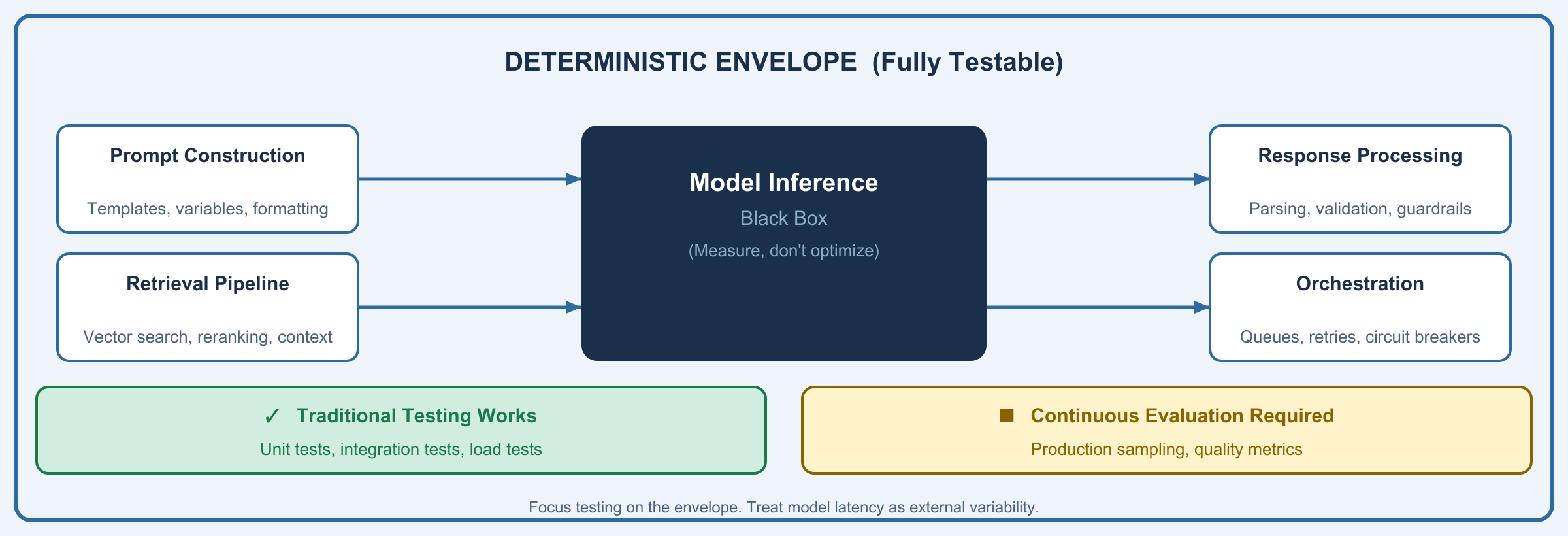
Prompt construction overhead. How long does it take to assemble your prompt from templates, user input, and retrieved context? At high throughput, string manipulation becomes measurable. Template rendering, context formatting, token counting. All of it adds latency before the model call begins.
Retrieval latency. For Retrieval-Augmented Generation (RAG) systems, your vector database query, reranking, and context assembly often dominate pre-inference time. This is entirely within your control and responds to traditional optimization: indexing strategies, caching, query optimization.
Response processing. Parsing model output, validating structure, applying guardrails, transforming for downstream consumers. All post-inference overhead you control. Streaming adds complexity: your processing pipeline must keep pace with token arrival without blocking.
Queue and orchestration overhead. Request queuing, load balancing across providers, retry logic, timeout handling, circuit breakers. This is your infrastructure for managing model calls. Under load, this scaffolding becomes the constraint, not the model itself.
The architectural insight: your performance testing strategy should focus on maximizing efficiency of the envelope while treating model latency as an external variable you measure but don't optimize. Mock the model call with realistic latency distributions and test everything else at scale.
Agentic Systems: Latency Budgets for Variable Execution
Agentic systems amplify every challenge. A single user request might trigger a planning step, multiple tool calls, retrieval operations, reasoning loops, and a synthesis pass. Total latency is the sum of: planning inference + (tool calls × tool latency) + (reasoning steps × inference time) + memory operations. Each component is variable. The number of components is variable.
Traditional Point-to-Point SLOs fail here. You can't set a p95 latency target when the 95th percentile depends on task complexity you don't control. An agent answering "what time is it" and an agent researching a complex topic aren't comparable operations, but they're the same endpoint.
The architectural response: component-level latency budgets with graceful degradation. Each agent component (planner, tool executor, reasoner, synthesizer) gets its own budget. When the aggregate budget is exceeded, the system must decide: continue and miss the SLO, or degrade gracefully?
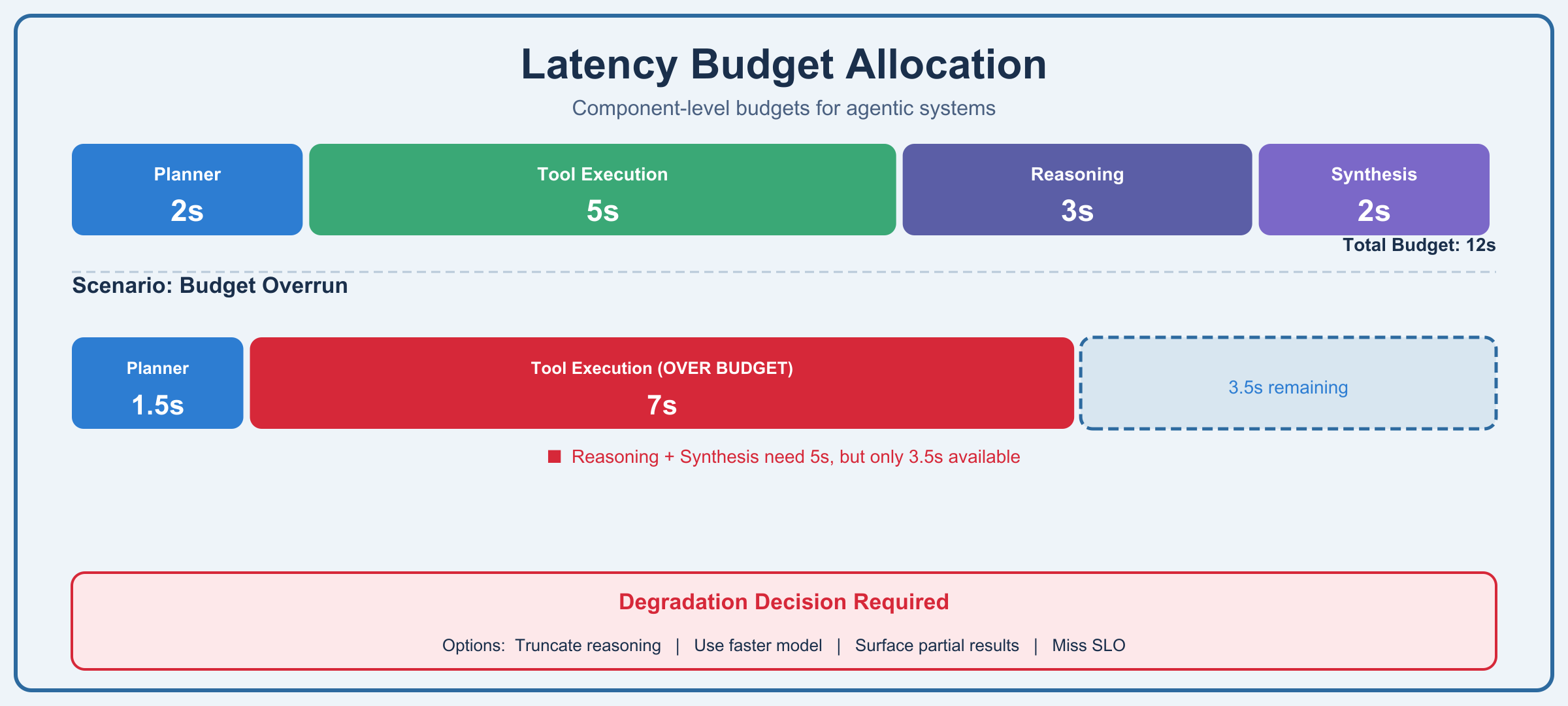
Consider how this plays out in practice. You allocate 2 seconds for planning, 5 seconds for tool execution (across potentially multiple calls), 3 seconds for reasoning, and 2 seconds for synthesis. Total budget: 12 seconds. The planner runs in 1.5 seconds, so you're ahead. Tool calls take 7 seconds, so you've consumed your buffer and then some. You now have a choice: attempt reasoning and synthesis with a truncated budget or invoke a degradation strategy.
Graceful degradation for agents might mean limiting reasoning depth, reducing tool call parallelism, using faster (lower quality) models for intermediate steps while reserving capable models for final synthesis, or surfacing partial results with explicit uncertainty markers. These aren't failure modes. They're designed operating points for when the latency budget runs out.
Your performance testing must exercise these degradation paths. What happens when the tool call budget is exhausted? When reasoning steps hit the limit? When total execution time approaches the ceiling? These scenarios require deliberate testing with synthetic delays, forced timeouts, and budget exhaustion triggers, not just load curves that measure happy-path throughput.
The New Performance Playbook
Performance engineering for LLM systems requires reframing, not abandonment. The discipline remains: measure, analyze, optimize, verify. But the targets shift.
Measure latency as a multi-dimensional vector: TTFT, token rate, total completion. Optimize across the speed-cost-quality surface, not along a single axis. Focus load testing on the envelope you control, treating model inference as external variability. Design agentic systems with explicit latency budgets and graceful degradation when budgets are exceeded.
The teams struggling with LLM performance are often those applying the old playbook to a system it wasn't designed for. The response times are too variable. The costs are unpredictable. The load tests are inconclusive. These aren't failures of performance engineering. They're signals that the model needs to evolve.
The opportunity is significant. Most organizations shipping LLM features have no coherent performance strategy beyond "hope it's fast enough." A systematic approach, even one that acknowledges the inherent constraints, creates meaningful competitive advantage. Fast, cost-efficient, high-quality AI experiences are rare. The teams that figure out how to deliver them consistently will define the next generation of user expectations.





Lets Hang!