Refactoring has been around for ages, and most programmers at least pay lip service to it. In my experience, people approach refactoring in one of two ways. They either build it into their day-to-day work as an integral practice, or they talk about it as an avalanche task—something that they do in very large chunks every other sprint or so.
If you’ve studied up on refactoring, you know that making it part of your daily practice is the way to go. You look at a piece of code you are trying to understand or are about to change, and if it is not in a good state, you refactor. Over time, your code base gets better, except for the parts that don’t.
Wait. Why wouldn’t your code get uniformly better over time when you refactor what you touch? The fact is that we don’t touch code in our code bases with uniform frequency. Some classes get touched about once every month or so, and some—well, you wrote them a long time ago and there’s a good chance that you’ll never modify them again. The net effect of this is that some parts of our code get better over time and other parts don’t. This isn’t as bad as it sounds. We leave the code that we touch in a better state over time, and we’ll find ourselves visiting fewer and fewer bad areas of code. There may be messy areas remaining in the code base, but the fact that we don’t work in them reduces their impact on us.
In short, “refactor as you go” is a heuristic that aims our effort toward the code that gets in our way when we are programming. If we apply it diligently, we end up working in better code more often.
The only problem with this chain of reasoning is that it’s hard to be diligent. Some code is downright scary. It’s easy to think that a particular long method doesn’t matter much or that the effort to refactor it won’t be paid back, but we don’t have to guess. We can gather information that helps us understand the impact of our refactoring decisions.
Let’s take a look at some of the information we can acquire from our version control systems. Figure 1 is a graph of the number of commits for every file in a particular project’s code repository. The files are sorted in order of increasing commits.
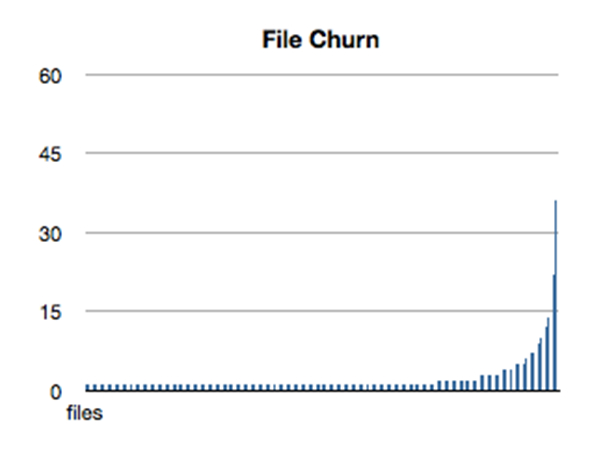
Figure 1
In this code base, we can see that there are some files that are changed extremely frequently, but the vast majority have only a few changes. This isn’t atypical. Most of the code bases I’ve created this graph for have roughly the same shape.
Looking at the figure, it seems that if we are going to spend time refactoring in our code base, we should concentrate on the files on the right side of the graph. Unfortunately, this isn’t the complete picture. Files can end up on the right for a variety of reasons. In some applications, there are some code files that are nearly configurational—they contain code for frequently changed settings or points of variation. Files containing factory classes are often in this category. They may be changed several hundred times over the life of the project, and, technically, there is nothing wrong with them. They aren’t the sorts of classes that inspire fear in our hearts.
To narrow down our refactoring candidates even further, we can take complexity into account. In figure 2, I’ve graphed the complexity for each file on the y-axis. The x-axis continues to show churn—the number of times a file has been modified.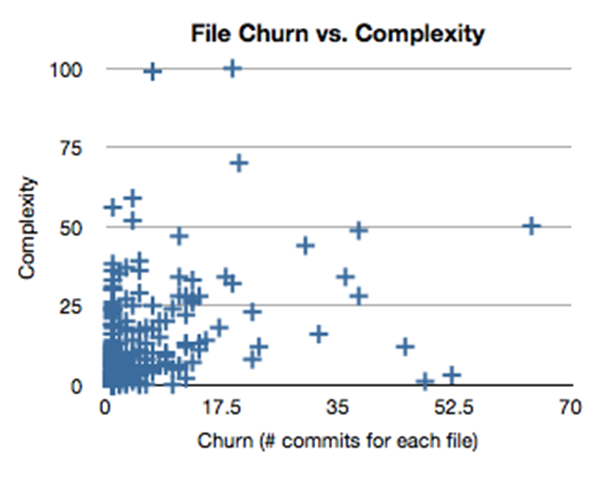
Figure 2
These diagrams give us quite a bit of information. The upper right quadrant is particularly important. These files have a high degree of complexity, and they change quite frequently. There are a number of reasons why this can happen. The one to look out for, though, is something I call runaway conditionals. Sometimes a class becomes so complex that refactoring seems too difficult. Developers hack if-then-elses into if-then-elses, and the rat’s nest grows. These classes are particularly ripe for a refactoring investment.
The other areas of the graph can give us some interesting indicators about the design style of the team. In healthy code, most of the files are in the lower left quadrant. I call this the healthy closure region. Abstractions here have low complexity and don’t change much. The upper left is what I call the cowboy region. This is complex code that sprang from someone’s head and didn’t seem to grow incrementally.
The last region—the bottom right—is very interesting. I call it the fertile ground. It can consist of files that are somewhat configurational, but often there are also files that act as incubators for new abstractions. People add code, it grows, and then they factor outward, extracting new classes. The files churn frequently, but their complexity remains low.
It’s rather easy to create these graphs. The project I used here is an open source project hosted on github. I wrote a small script to grep the log of the repository for all file adds and modification. Then, I sorted the list and use the uniq command to get the number of changes for each file. If you have a tool handy that computes some complexity metric at the file level, you can aggregate data for the other axis. I used the free tool SourceMonitor.
If we refactor as we make changes to our code, we end up working in progressively better code. Sometimes, however, it’s nice to take a high-level view of a code base so that we can discover where the dragons are. I’ve been finding that this churn-vs.-complexity view helps me find good refactoring candidates and also gives me a good snapshot view of the design, commit, and refactoring styles of a team.
Quite often, metrics views of code are restricted to static measures of code quality. Adding the time dimension through version-control history gives us a broader view. We can use that view to guide our refactoring decisions.
