When building large test suites, one problem that crops up is test case redundancy. Test suites are especially vulnerable to this when many members of the test team are writing test cases. The likelihood of one engineer writing test cases that are somewhat covered by another engineer's is very high. This results in duplication of effort when executing the tests. I will present some strategies for avoiding this problem when constructing the test suite, as well as methods for maximizing efficiency with your test suite.
I don't know about you, but the way we did things at our start-up company wasn't exactly ISO 9000 compliant. Often, when the entire team was testing the product just weeks before release, trying to get through that last bit of functional and regression testing before shipping, people would be saying things like, "Hey, did you run that test on Win2k? Good, I can pass my test case" or "Oh, you're downloading that content too? That's what I'm doing!"
This indicates test case duplication in your test suite. Redundancy is but one problem that plagues inefficient test suites. Other problems can include lengthy, laborious test cases that return very little added value, and system-level test cases that aren't validating the system properly. I will take a look at each of these problems individually, and suggest techniques that may help you when designing a test suite, or when fixing your current one.
Overlapping Functional Areas
Let's approach testing a system from a conceptual level first. Functionality in and of itself is useless to any system. A "find" feature is only useful when you have a document that needs searching. A "download" is only useful when you have a server or peers from which to acquire content. Viewing email is only possible when delivered by a mail server. These examples illustrate the necessary presence of integration points. All of us are well aware of integration testing, and we understand that functionality doesn't exist in a void. Functionality happens when it is enabled, so to speak, by integration points with other functionality. Integration of functionality means that data or communication is somehow shared between that functionality--that's what makes it work! But, as we shall see, that's what makes it hard to test as well.
Sometimes the lines between functional areas are so closely tied by their integration points that it's very difficult to distinguish between the two (or three, or four). This can make for some difficulty in determining where a functional test should begin,where it should end, and at what point another functional test should pick up and continue testing other functionality. In other words, when the line between functionality is blurred, so is the line between test cases, and that can lead to test case overlap, and in some cases, outright test case duplication.
Let me illustrate this with an example. Let's say our crack-shot test team is testing a brand new media player named FooPlayer. FooPlayer is a simple media player that has basic functionality such as playing multiple audio file formats, volume controls, and the like. One logical breakdown for test ownership among our team members might be:
- Bob: Install, launch, shutdown
- Lucy: File-format support
- Suzy: GUI interface
Now, let's look at what each tester might do when performing a very simple test of their functional area. Bob runs a simple test:
- Install FooPlayer: verify installs properly
- Launch FooPlayer: verify launches properly
- Shutdown FooPlayer: verify shuts down properly
- Uninstall FooPlayer: verify uninstalls properly
Now, what would Lucy's test look like if she were testing a media type?
- Launch FooPlayer: verify launches properly
- Open an .MP3 file: verify FooPlayer accepts file
- Play .MP3 file: verify FooPlayer plays the file
- Stop .MP3 file: verify file stops playing
- Shutdown FooPlayer: verify shuts down properly
And what would Suzy's test look like to test a GUI control like volume?
- Launch FooPlayer: verify launches properly
- Open an .MP3 file: verify FooPlayer accepts file
- Play .MP3 file: verify FooPlayer plays the file
- Adjust volume: verify volume changes according to adjustment
- Stop .MP3 file: verify file stops playing
- Shutdown FooPlayer: verify shuts down properly
Notice anything here? Even though the divisions of functional areas seemed logical, it's very clear that Lucy and Suzy are performing the same test case, they are just validating different things. This is a very important concept for maximizing efficiency in your test suite. Validation points are very important concepts with test case writing because without always considering what you are validating, you could very well be writing the same test cases over and over again, just from a different perspective.
Notice as well that both Lucy and Suzy are exercising the launch of the player--but they aren't validating it. An execution step that doesn't validate itself is a wasted step, because there will always need to be another test case that does the same thing that is validating itself. In this case, Bob is launching the player in his test case, an action that has already implicitly been tested by both Lucy and Suzy.
Granted, the above illustration is very simplistic, but the point remains: Streamlining your test suite requires that care be given to the validation points of that test case. As an exercise to further illustrate this concept in your own test suite, try taking some areas of functionality and making a matrix out of the steps required to perform the test case. You will see the overlap. Here's an example of the matrix for the above set of test cases:
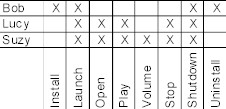
See if such analysis yields any results for your test case organization, and you may be surprised.
Overly Complicated Test Cases
Another source of inefficiency in many test suites is the writing of test cases that are lengthy with very little return value. Granted, they don't seem like it at the time they are written, but they can be costly when forced to execute many times throughout the course of a project. If these sorts of test cases are automated, then they can be as complex as necessary, and automation will either make quick work of them, or allow running during off-hours so work hours are not spent chasing down lengthy processes. If your test suite is littered with test cases that seem to be the "hard ones nobody wants to do," there will be a high cost associated with them (especially later in the project) and all measures should be taken to ease their execution.
I'll give you an example. I worked at a company doing multisource downloading (a download that gathers segments of the file from multiple servers or peers, rather than downloading the entire file from a single server), we would often spend hours setting up a test scenario in our lab. We had to download the same content onto a number of peers, validate that the content was successfully there, then set up a machine to do another download of that content, actually download the content from that machine, and verify that the download had in fact been gathered from the peers we had already set up. It took hours to execute a couple of iterations of this.
The problem with test cases of this sort is that they have to go through so many steps that are already being tested by other test cases, just to get to the validation point, which in this case was a simple multipeered download. Why not just eliminate those steps and go straight to the download? We accomplished this by setting up a few peers that always hosted the content and were never touched. Then, when someone had to execute that test case, they simply downloaded, verified, and moved on.
Improper Validation
The last problem that can diminish efficiency with test execution is the writing of system-level test cases that aren't validating the system properly. As we have seen, even though a test case performs actions that may be systemwide, it is vital to validate across those system points. A system-level test case that has a single expected result (i.e., ends with "and verify it does this") isn't being written with maximum efficiency because even though many parts of the system were exercised with the test case, they weren't validated, and thus, didn't get tested.
Imagine you are writing a simple system-level test for a Web site offering downloads, like Download.com or MP3.com. Even simply downloading a file is a system-level test. Clicking on a download link on the site sends a request back to the Web server, which executes some code, which does a database lookup to retrieve the file info, which requests the file from a file server somewhere, and sends it back to the browser. Inherent in that simple operation is probably logging and authentication as well. Just trying to get the file would certainly verify that components in the system were working, but if the process is going to be taken, why not expand the validation points and check the logging and authentication as well? With one operation you have validated not only the core functionality, but the supporting functionality as well.
With these test case writing techniques, you can achieve a higher degree of efficiency with test execution. Being mindful of test case duplication can streamline test execution so that your testers aren't duplicating effort. Breaking out long, involved test cases into easier chunks can not only accomplish the testing faster, but also avoid the dreaded feeling of having to execute them, which can be a time drain in and of itself. Additionally, expanding the number of validation points for system-level test cases can increase test coverage you are already implicitly performing. Overall, these techniques together can save considerable time on any test project.